
Dolt is a SQL database with Git-like functionality. It supports version control primitives including commit, branch, merge, clone, push and pull. This is the fourth post in a series exploring how Dolt stores table data implements these version control primitives. Previously, we looked at the content-addressed sorted index structure underlying Dolt’s table storage, called a Prolly-tree. In the second post, I explained the Dolt commit graph and how table storage in Dolt is shared across revisions of the table. In our last post, we talked about implementing diff efficiently on top of Prolly-trees.
In this post, we’re going to look at how Dolt implements merge by using a
cell-level three-way merge algorithm.
Overview#
Merge is a fundamental operation in (D)VCS and finding a way to do effective merges of source files in version control systems is what allowed VCS implementations to move away from file locking and into a workflow where multiple people can work on the same files at the same time.
A merge takes two divergent revisions of a source document which are created
by two divergent histories of changes to that document and produces a new
document that includes all the changes from both histories. In the context of
Dolt where the “source document” is the value of the database at a commit, the
fundamental operation is something like newDatabaseValue := Merge(intoDatabaseValue, fromDatabaseValue).
The fundamental question is how to construct the newDatabaseValue given the
two database values which should be merged. There have been numerous solutions
to this problem in a variety of contexts, including collaborative file
editing, databases and version control systems. Dolt takes its approach to
merges from Git, and it implements a traditional algorithm from VCS, a
three-way merge.
Three-way Merge#
A three-way merge works in the context of the commit graph and a recorded and
available history for how the database came to have intoDatabaseValue and
fromDatabaseValue. It builds on top of diff, which was explained in
my previous blog post and it
works on three independent commits:
-
into—The head of the branch being merged into. Often something like
main. -
from—The head of the branch being merged from. Often a feature branch.
-
ancestor—The nearest common ancestor of into and from.
On a Dolt commit graph, with the commits pointing to their parents, this looks something like:
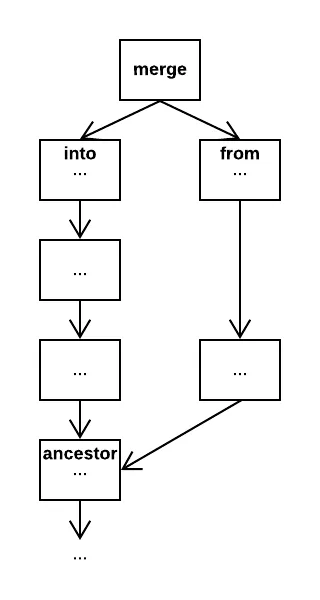
When running dolt merge, into and from are explicit based on the
working directory and the CLI invocation. into comes from the branch that
is currently checked out in the working directory. from comes from the
commit that is supplied on the command line. But ancestor is based on the
repository state and relationship between into and from. It is found
automatically by inspecting the parents of into and from.
The nearest common ancestor is the ancestor where the commits most recently diverged from each other.1 We find this commit by walking the parents of into and from in breadth-first order until we find a common commit.
Diffs and Finding Conflicts#
The fundamental observation of three-way merge is that if we look at all the changes between ancestor and into and all the changes between ancestor and from, that is the set of changes that should appear in the value that results from the merge of into and from.
Diff(ancestor, into) defines all the changes that have occurred on into
since it diverged from its common ancestor with from. And symmetrically,
Diff(ancestor, from) defines all the changes that have occurred on from
since it diverged from its common ancestor with into. If all of those
changes are reflected in the database value resulting from Merge(into, from), the value will be the one we want.
Dolt does this by merging the diffs by primary key on table data for each
table in the database. After finding the commit ancestor, it streams
Diff(ancestor, into) and Diff(ancestor, from). It visits differences in
primary key order using a merging iterator of the two diffs.
-
If
Into.Key < From.Key: the value for the row inintois the right value in the output. -
If
Into.Key > From.Key: the value for the row infromis the right value in the output. -
If
Into.Key == From.Key && Into.Value == From.Value: the same change was made inintoandfromand there is no conflict. The value of the row is as it is inintoandfrom. -
Otherwise,
Into.Key == From.Key, but the rows are not identical. In this case, Dolt falls back to cell-level merge of the rows.
A cell-level merge means that the merged value for that row is not a conflict if the changes didn’t touch the same columns. Specifically:
-
If one of the changes is a delete and the other is not, then there is a conflict.
-
If, for any column α in the table,
intochanges the value of column α to be χ, andfromof the changes the value of column α to be γ, where χ is not equal to γ, then there is a conflict -
Otherwise, the value of the row in the merged output is equal to the value of the row as it appears in ancestor, with all of the column mutations in into applied to it and all of the column mutations in from applied to it.
Here’s an example of the two diffs merge might be operating on:
+-----+------------+------------+------------+ +-----+------------+------------+------------+
| | name | population | capital | | | name | population | capital |
+-----+------------+------------+------------+ +-----+------------+------------+------------+
| + | california | 39510000 | sacramento | | + | new york | 19378102 | albany |
| < | texas | 29000000 | austin | | < | texas | 29000000 | austin |
| > | texas | 25145561 | austin | | > | texas | 28995881 | austin |
| - | usa | 328000000 | dc | | - | usa | 328000000 | dc |
| < | vermont | 600000 | windsor | | < | vermont | 600000 | windsor |
| > | vermont | 623989 | windsor | | > | vermont | 600000 | montpelier |
+-----+------------+------------+------------+ +-----+------------+------------+------------+
In this example, california will be covered by case #1, new york
by case #2, and usa by case #3. texas, because it is modified in
both branches and has a conflicting column value, will end up as a
conflict in case #4. vermont will also be handled by case #4, but
because the two branches modified different columns, there will be no
conflict. The resulting row will reflect both changes: a population of
623,989 and a capital of Montpelier.
In reality, when implementing the above algorithm, Dolt is operating on an
editor for the table data in into, not ancestor. Thus, Dolt skips over
entries matching step 1 and 3, it applies all the diffs matching step 2 to the
current table value, and it applies the cell-level diffs on non-conflicting
changes matching step 4 only from from.
Dolt’s three-way merge works great in the case that the two divergent
histories work on independent parts of the database. But if they both update
portions of the database with conflicting values, then it fails to produce a
database value that incorporates both sets of changes. Instead, it falls back
to producing conflicts and it leaves it up to the user to resolve conflicts
and get the database into a state that reflects both sets of changes.
Representing Conflicts#
The result of the merge algorithm is a new table value for the table in the working set plus a possibly empty set of conflicting rows which could not be merged successfully. Conflicts in Dolt are always on a row in a table. The primary key is the same between into and from, but the values for at least one column in the row were different between the two commits and that column’s value was changed by both histories since ancestor.
Conflicts in Dolt are stored by primary key along-side the table data for the table, in a separate Prolly-tree from the table data itself. Each row in the conflicts Prolly-tree stores the value of the row as it appeared in all three commits involved in the merge: into, from and ancestor . This allows for programmatic resolution strategies to see the relevant row-related data if necessary.
Conflicts after a merge can be resolved one-by-one, by setting the row to a certain value and removing the conflict from the conflicts row data. Dolt also has built-in bulk resolution strategies, such as take-ours and take-theirs. For example, to merge a feature branch into your current working branch and overwrite all conflicts back to their values as they are in your current working branch, you an do:
$ dolt merge feature-branch
$ dolt conflicts resolve --ours table_with_conflictsCurrently Dolt considers any table that has unresolved conflicts in its
conflicts Map to be unmerged and it will not allow a commit to be created with
any unmerged table values. That means that table values that carry conflicts
cannot appear in commits. This is a small divergence from git, which places the
conflicts as textual markers directly in the working tree (if those files are
text files) and will allow files with conflict markers to be staged for commit
with something like git add -f.
Conclusion and Future Work#
We took a quick look at how three-way merge works and saw that it applies very naturally to table data as Dolt represents it. While a cell-level three-way merge isn’t the most natural fit for every database merge use case, we think it’s a really good starting point for human scale databases that have feature-level collaboration. That being said, this space is one corner of Dolt that’s ripe for innovation, and we hope to see a lot of feature work here in the future. Some things we would to implement include:
-
Recursive three-way merge, for when a nearest common ancestor is not uniquely defined.
-
A larger suite of conflict resolution strategies, potentially building on type-specific merge-lattices from CRDTs for example.
-
A larger suite of conflict generation strategies. Cell-level conflicts is reasonable in a lot of cases, but row-level is more appropriate for some database schemas, and its not hard to imagine cascading or windowing conflict strategies as well.
-
Programmatic conflict resolution support, so that users can bring domain-specific logic.
-
Better handling for row-level conflicts caused by constraints, foreign keys, etc.
-
Better tools for working through schema merge conflicts.
If you have any feature requests in this space or any use cases that aren’t currently well handled by the cell-level, please reach out to us.
Footnotes#
-
It’s possible for cross-merges to mean that the nearest common ancestor of two commits is not uniquely identified. In the three-way merge case, there can be at most two nearest common ancestors. Git uses a recursive three-way merge algorithm to handle this case, where the two nearest common ancestors are themselves merged to form a nearest common ancestor on which to run the algorithm. This is something that is not implemented in Dolt yet. ↩