The Dolt Commit Graph and Structural Sharing

Dolt is a SQL database that provides Git-like functionality, including clone, push, pull, branch, and merge. This post is part of a series exploring how Dolt stores table data. In our previous post, How Dolt Stores Table Data, we explored a unique sorted tree data structure called a Prolly-tree that forms the basis of Dolt's table storage. In this post, I wanted to talk a little bit more about how table values are mapped onto a Prolly-tree and the implications that has for structural sharing, or how storage is shared across versions of the data, in Dolt.
Dolt Commit Graph
To implement Git-like functionality in a SQL database, Dolt stores a
merkle DAG of the commit graph of a Dolt repository. A Dolt commit
looks a lot like a Git commit, except that it stores the value of the
entire database within each commit, instead of storing a Git
file-system-like tree. In particular, each Dolt commit contains:
- An author.
- A commit message.
- A timestamp.
- A set of commit parents.
- A value of the database at this commit.
The most interesting part for our discussion is the "value of the database". To Dolt, the value of the database at a given commit needs to encode the schema of the entire database, all of the rows in all of tables of the database and—unique to Dolt—any unresolved conflicts for any table data. So Dolt encodes a database value as a map from table names to a table value. A Dolt commit graph might look like:
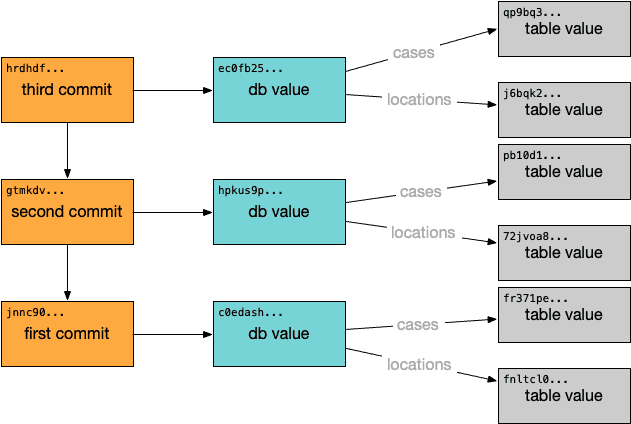
A table value in turn includes the schema for the table and the table data, encoded in a Prolly-tree. A table value looks something like:
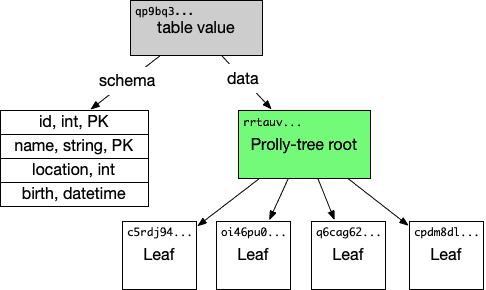
The purpose of the Prolly-tree is to allow efficient structural sharing of table data across various versions of the data, while maintaining efficient query processing and enabling efficient operations like diff. I want to explore the structural sharing aspect a little bit and talk about storage requirements in the presence of versioning.
Structural Sharing in Dolt
If you are building a versioned database that provides Git-like functionality, something you might want to do is efficiently store n database values that are all small deltas of each other. Ideally, storing those values would have a storage cost proportional to n times the size of the delta between the values, as opposed to n times the total size of the data. There are a number of possible designs for achieving such behavior in a variety of circumstances, and Dolt picks a particular place in the design space.
As explained in our previous blog post on Dolt storage internals, Dolt stores table rows in a Prolly-tree. Structural sharing in Dolt happens at the Prolly-tree chunk layer. When a table changes and a commit is made, two different commits will reference two different database values. Those database values will in turn reference two different Prolly-tree roots for a given table value. But the internal nodes of the two Prolly-trees will typically contain many of the same chunks, and so the storage requirements for storing both values together will scale with the size of the changes, as opposed to the size of the database times the number of versions.
Some concrete factors of how Dolt stores data factor into how structural sharing behaves. These are some relevant details:
-
All table data is currently stored row-major.
-
Table data is stored in a clustered index on the primary-key columns of the table.
-
Leaf nodes in the Prolly-tree are stored compressed with Snappy.
-
The chunk boundaries for the chunks are chosen based on a snappy-compressed1 byte stream of the encoded chunk values, not the pre-compressed data.
-
The probabilistic chunking within Dolt targets a compressed block size of 4KB.
Knowing all of this allows us to pretty quickly formulate some intuition for how structural sharing will play out in different scenarios. Here are some quick observations:
-
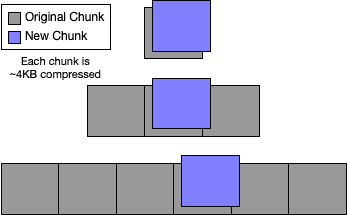
The absolute smallest overhead for any mutation to a table is, on average, a little larger than 4KB times the depth of the tree. Typically changing the value in a chunk won't change the chunk boundary, and you'll need to store complete new chunk values for the new leaf chunk and all the new internal chunks up to the root. The best case scenario looks like:
-
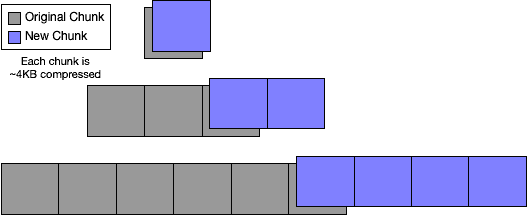
Adding rows to a table whose primary keys are lexicographically larger than any of the existing rows in the table results in an append at the end of Prolly-tree for the table value. The last leaf node in the tree will necessarily change, and new chunks will be created for all of the new rows. Expected duplicate storage overhead is going to be the 4KB chunk at the end of the table's leaf nodes and the spline of the internal nodes of the map leading up to the root node. This kind of table might represent naturally append-only data or time-series data, and the storage overhead is very small. This looks like:
-
Adding rows to a table whose primary keys are lexicographically smaller than any of the existing rows is very similar to the case where they are all larger. It's expected to rewrite the first chunks in the table, and the probabilistic rolling hash will quickly resynchronize with the existing table data. It might look like:
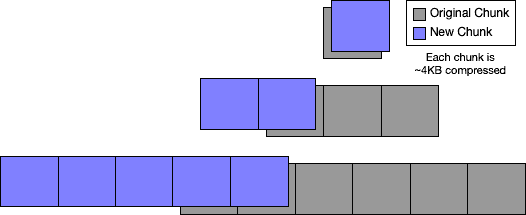
-
Adding a run of data whose primary keys fall lexicographically within two existing rows is very similar to the prefix or postfix case. The run of data gets interpolated between the existing chunks of row data:
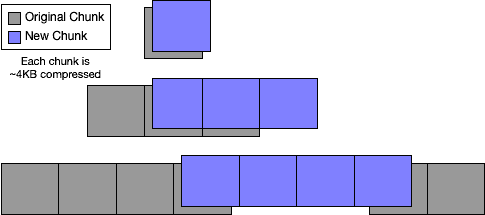
Hopefully those four examples allow you to form some intuition for how different use cases will affect the size of a growing Dolt repository over time.
When Dolt (Currently) Can't Structurally Share
The previous few examples show things working out pretty well. But there are some other cases to be aware of as well: when structural sharing in Dolt's current model breaks down pretty substantially. These are some cases that are worth pointing out, just to be certain you are aware of them:
-
Dolt doesn't store null-valued columns in the row-tuple, so you can add a nullable column to a table without affecting table row storage at all. But if you populate that column for every row in the database, that ends up affecting the entire Prolly-tree. There will be no structural sharing across the Prolly-tree for the row data of the table in new and the previous commit. In the future, we would like to provide more options around table storage and the row-major layout of table data in order to get around this limitation. Something like explicit column families might work very nicely here, if we have use cases that run into this and see it as a substantial hurdle.
-
Even the smallest edit to table data results in storage costs of ~4KB times the depth of the tree. Depending upon your use case, that can still be pretty substantial storage amplification.
-
Lots of random edits scattered throughout the database can also amplify storage in a similar way. For example, let's say you have an average row size of 128 bytes and you're getting a factor of 2 compression out of the chunk-layer compression. That means on average there are 64 values stored in every chunk. If some process updates 1/64th of the values in your database, with a completely random spread across the keys, you can expect structural sharing to be very poor across that edit.
Some of these cases are far from pathological, and we hope to improve all of them in the future. But they're the reality of Dolt's storage layer today and they can be good to know about.
Conclusion
We briefly explored Dolt's commit graph and table storage, and reviewed some factors that effect storage amplification when storing a complete history of a SQL database in a Dolt repository.
Dolt's implementation of table storage allows it to share storage for similar versions of database tables in many cases, while also maintaining efficient query processing across any version of the table. In order to achieve that, Dolt makes some concrete trade-offs. Many common use cases will see lots of structural sharing and little storage amplification when using Dolt to store versioned database tables.
- In actuality, in order to improve structural sharing, the chunk boundaries are chosen based on a modified snappy compression algorithm that is less likely to cause cascading chunk boundary changes when mutating a value. See this code comment for details.↩