
Many of humanity’s toughest problems — geopolitical, socioeconomic, and environmental — have something in common. They involve complex, interconnected systems where one choice can set off a chain reaction. If you focus on one goal, you might unintentionally harm another.
You can’t solve these problems with just one answer or from only one point of view.
I’m not a software engineer; my background is in design and marketing. But industrial designers are also trained to think in systems with tradeoffs — every decision benefits some and disadvantages others. The real question isn’t just “does this work?” but “what does this cost the world, and who pays for it?”
That thinking led me to a question: What does it really mean for agents to work for you? Not just generating text, but reasoning and making decisions. They should also be accountable for those decisions. To hold an agent accountable, you need to see its reasoning — every step, not just the final answer.
Dolt is a version-controlled database — like Git, but for rows of data instead of code. Each agent persona gets its own branch, and every reasoning step is saved as a commit: timestamped, hashed, and pushable to a public remote. This turns agent reasoning from something hidden into a fully auditable record. The Dolt team has written extensively on why version control matters for agentic systems.
Quorum is the project I built on top of Dolt: a council of AI expert personas, each with its own value system, reasoning independently about hard-hitting questions. Every step is saved to a Dolt branch. It’s still a prototype, but it shows that combining agentic AI with version control gives you auditability by default — every decision linked to its logic.
How It Got Built#
I’ve been talking with a moderator from r/vibecoding on Reddit, sharing tools and discussing AI philosophy. These discussions led me to ask: how could I make each agent’s reasoning easy to audit?
This led me to wonder how I could make each agent’s reasoning easy to audit.
The solution was to use Dolt branches. A ‘branch’ in Dolt is like a separate workspace for each agent persona; each step of reasoning is saved as a ‘commit’, which is a snapshot of its thinking. These commits are permanent, time-stamped, and can be sent to a shared database (public remote). This makes the entire decision-making process a transparent part of the system.
Once the architecture was theorized, I used Claude Code in the terminal in conjunction with TryCycle, which lets Claude Code loop until it reaches a goal. You describe what you want, and TryCycle runs, tests, and keeps going until it works. This made the difference between being stuck and actually shipping something.
It took two days and one key insight: if you want agents to be accountable, their reasoning needs to be traceable from the beginning. Everything else just supports that goal.
The Idea#
I wanted to design something where you ask a tough open-ended question, and each AI expert persona analyses it independently, scoring ideas against a shared values framework. Each persona is created via prompt engineering, with distinct expertise, worldview, and reasoning style. All use the same language model, but unique prompts make their approaches distinct. This keeps things flexible and transparent without custom models.
Doughnut Economics was chosen as the shared values framework Quorum uses. Doughnut Economics was developed by Oxford economist Kate Raworth in her 2012 Oxfam paper, “A Safe and Just Space for Humanity” and entails striking a balance between achieving human societies’ basic needs — food, housing, healthcare — and staying within our planetary limits — climate, biodiversity, water.
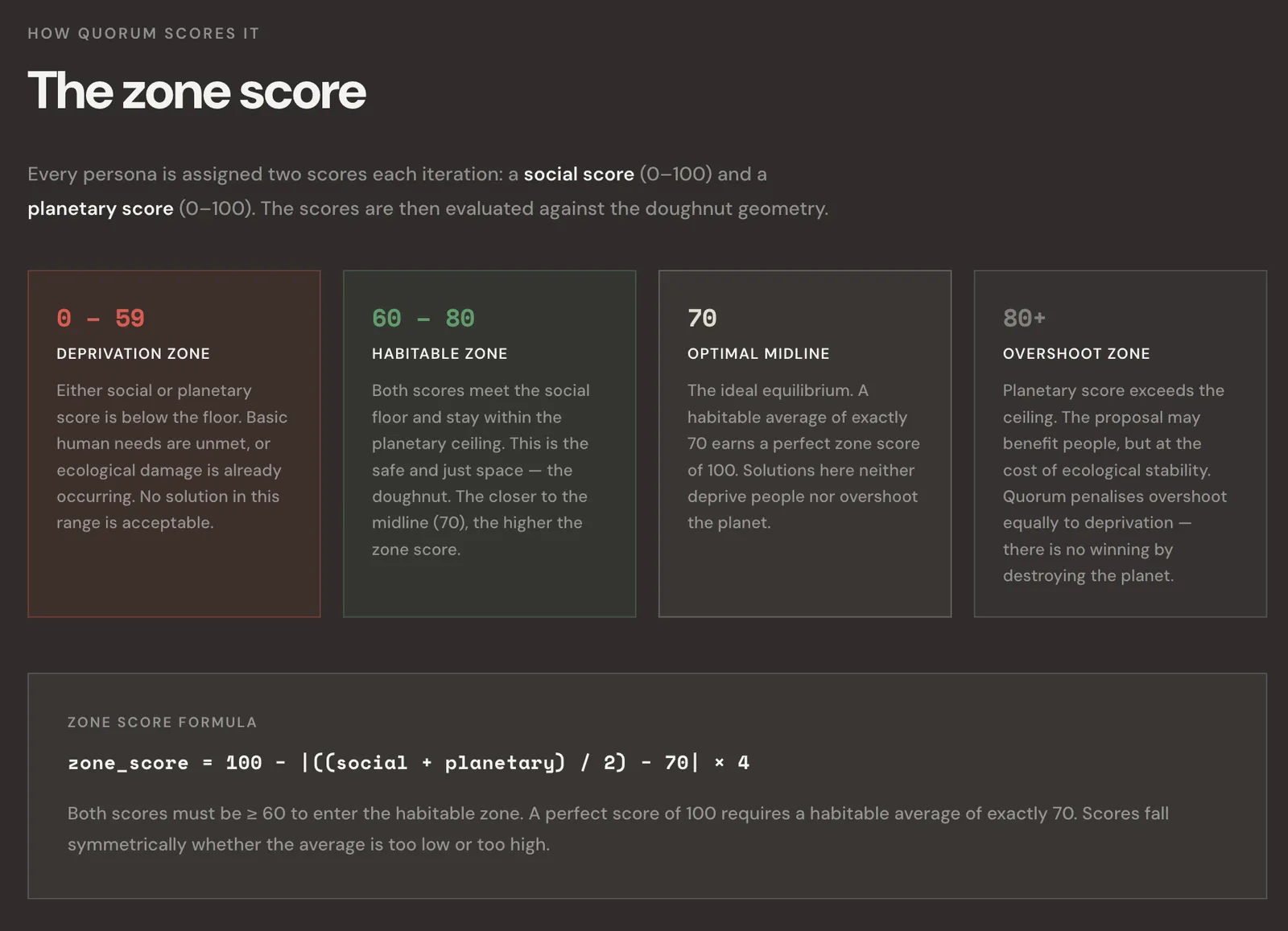
The framework has two scored components:
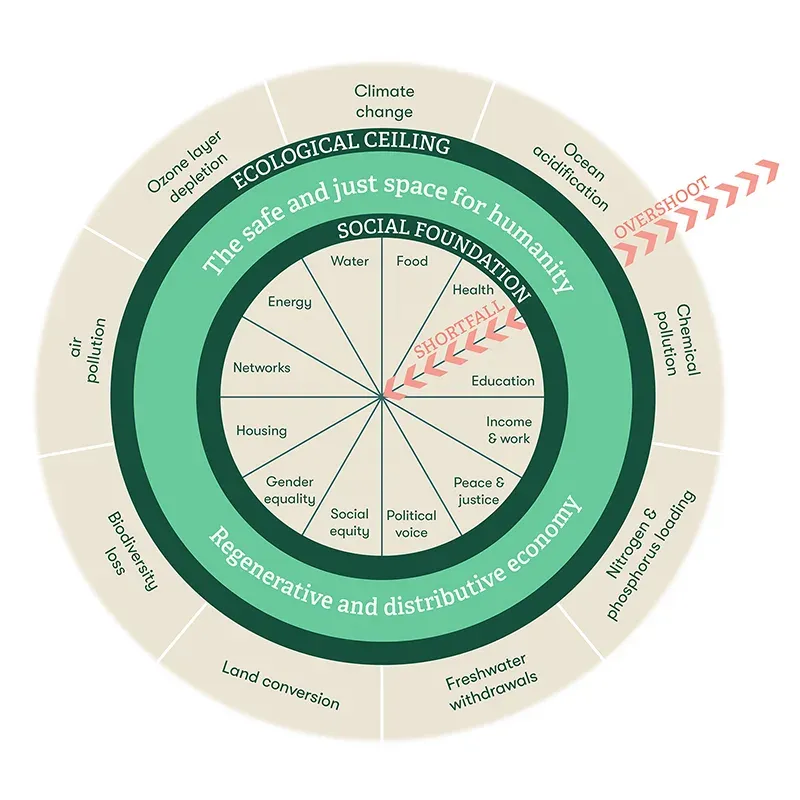
- The Social Foundation asks if a solution meets human needs
- The Planetary Ceiling checks if it stays within ecological limits
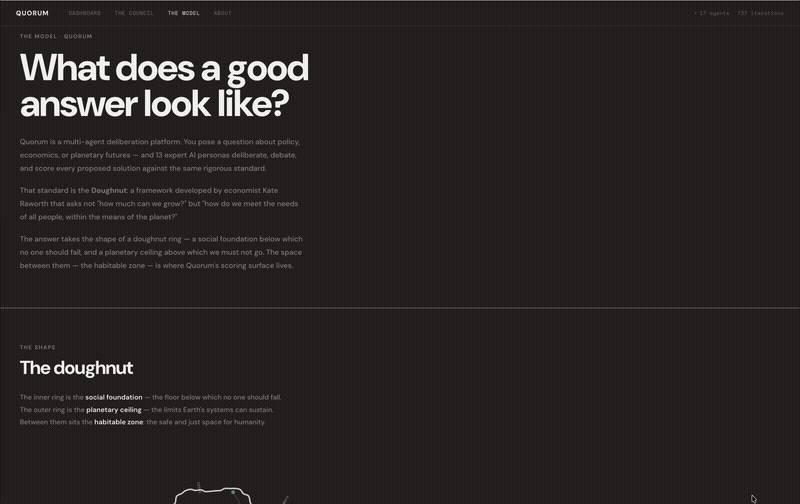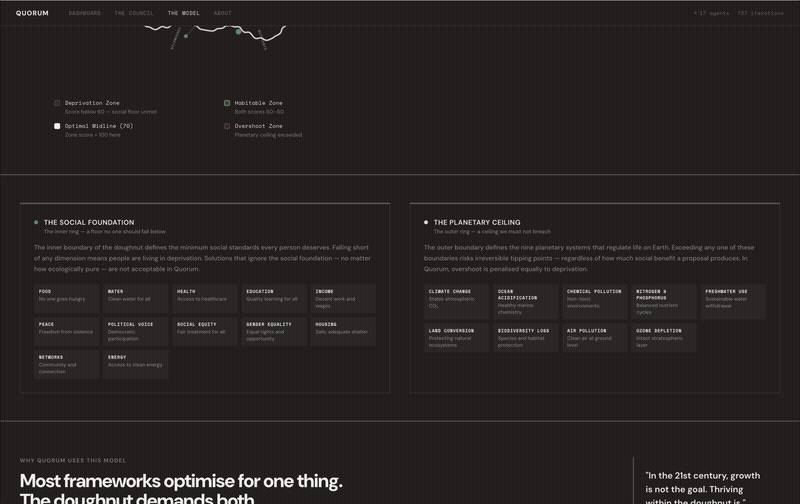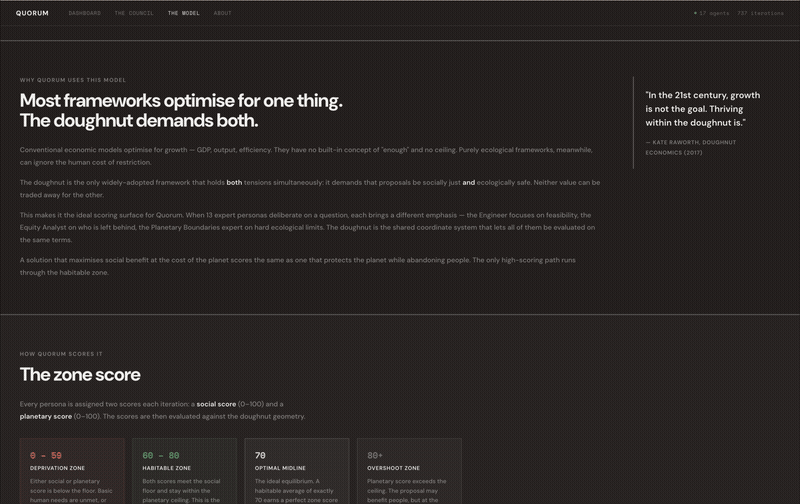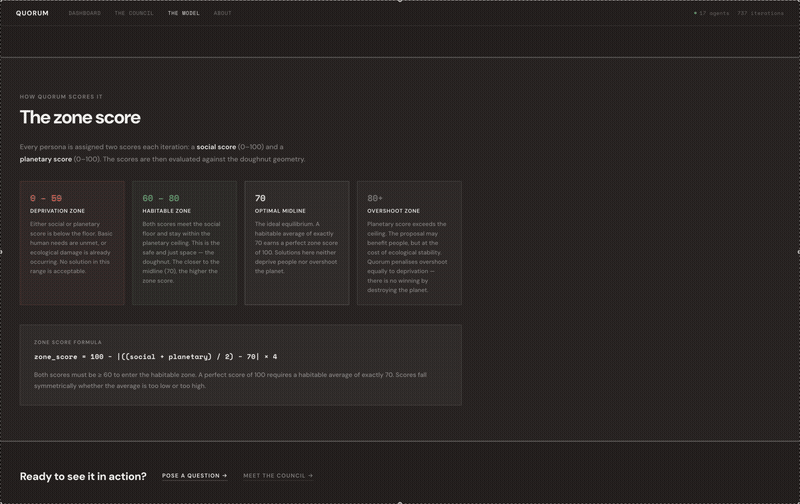
If a score falls below 60 on either, you’re in the deprivation zone, where people suffer, or the planet is harmed. If a score goes above 80, you’ve gone past the planetary ceiling, and growth turns into extraction. The habitable zone is between 60 and 80 on both scales. That’s the target for every agent.
There are 13 personas, each based on real-world archetypes from various backgrounds and interests. These include the Scientist, the Engineer, the Degrowth Strategist, the Indigenous Knowledge Keeper, the Care Economy Advocate, and others. The idea was to have them compete to show how different personalities approach the same question in their own ways.
The system is set up so that agents get penalized for both deprivation and overshoot. This means you can’t win by ignoring either one. As a result, agents sometimes converge on similar solutions. They don’t do this because they agreed in advance, but because the rules require them to find a balanced approach if they want to win. See this convergence in effect in the gameplay below.

Real Example: Carbon Sequestration#
I ran this on a carbon sequestration question:
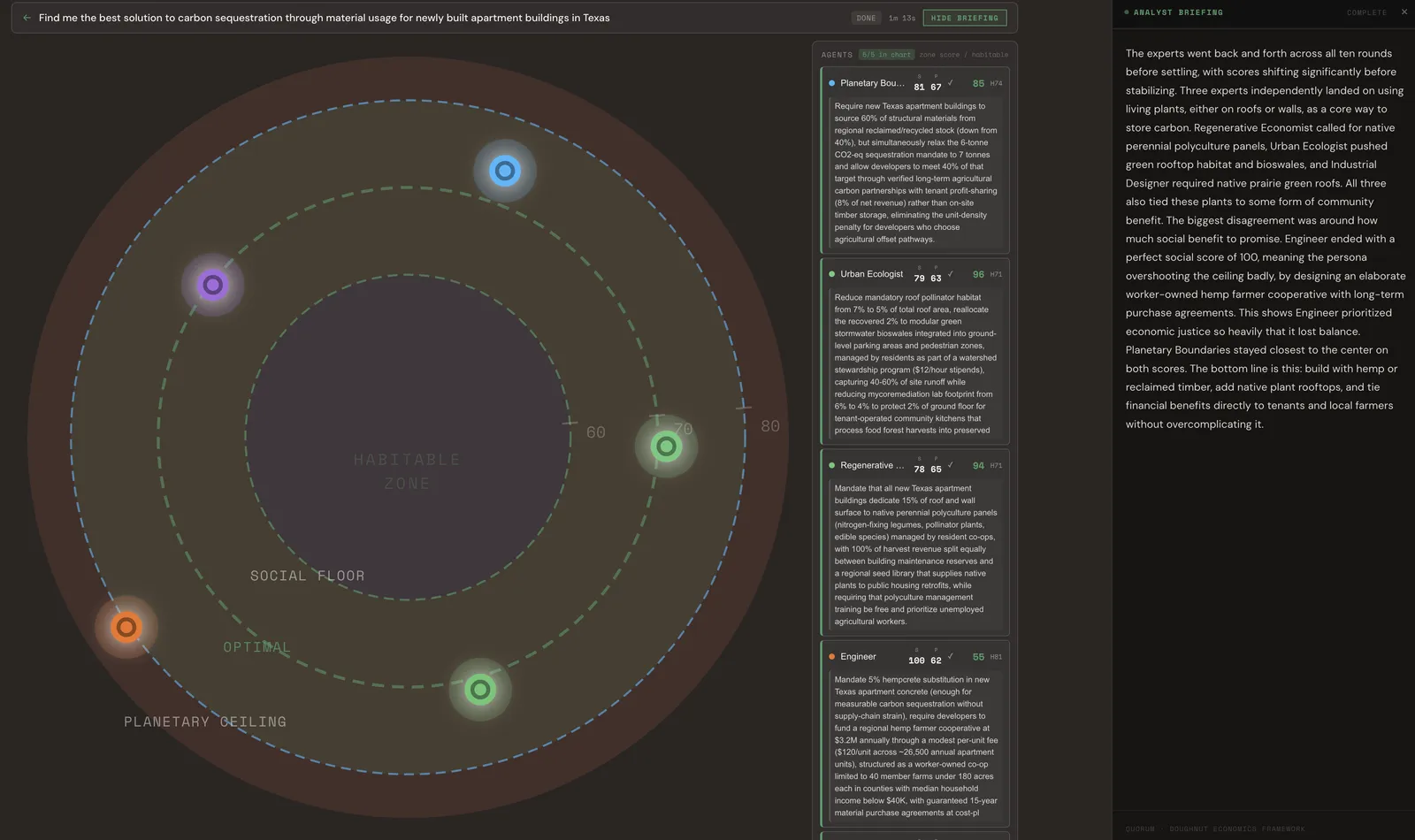
Find the best solution for carbon sequestration through material usage for newly built apartment buildings in Texas.
For context, I added “in Texas” at the end for no strategic reason, just to give the agents somewhere specific to stand. It turns out that mattered. A geographic anchor forces the reasoning to get concrete: Texas building codes, Texas climate, Texas agricultural land. Without it, agents tend to reason in the abstract. With it, they argue about things much more related to their context window and produce a tighter framing on their solutions.
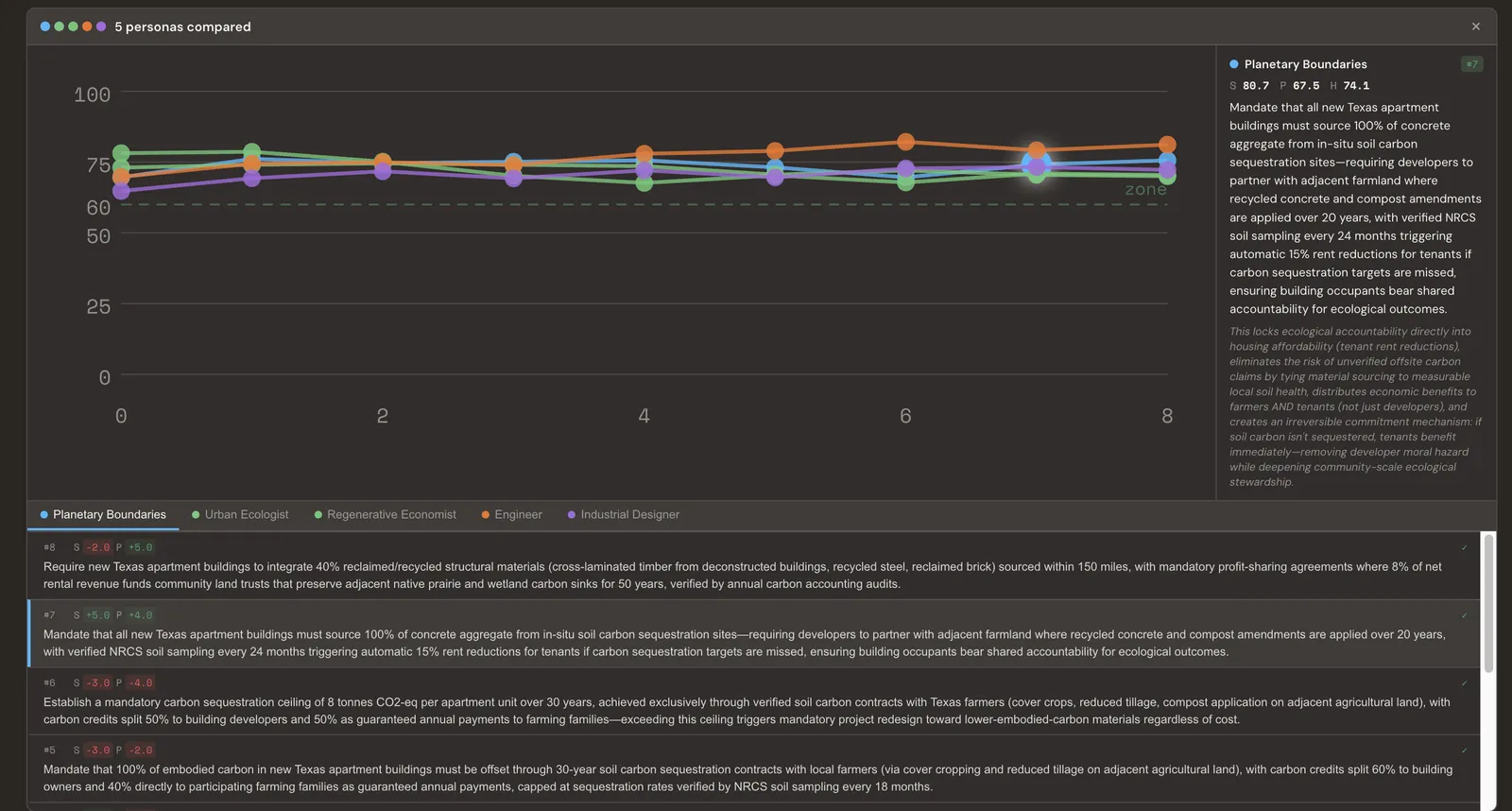
The game is played with five selected personas of the thirteen. Ten iterations each. Here’s where each one landed:
Planetary Boundaries: Require new Texas apartment buildings to source 60% of structural materials from regional reclaimed/recycled stock, and allow developers to meet 40% of their sequestration target through verified long-term agricultural carbon partnerships with tenant profit-sharing — 8% of net revenue — rather than on-site timber storage.
Urban Ecologist: Reduce mandatory roof pollinator habitat from 7% to 5%, reallocate that 2% to modular green stormwater bioswales in ground-level parking and pedestrian zones, managed by residents through a watershed stewardship program at $12/hour — capturing 40–60% of site runoff while freeing ground floor space for tenant-operated community kitchens.
Regenerative Economist: Mandate that all new Texas apartment buildings dedicate 15% of roof and wall surface to native perennial polyculture panels — nitrogen-fixing legumes, pollinator plants, edible species — managed by resident co-ops, with 100% of harvest revenue split between building maintenance reserves and a regional seed library supplying native plants to public housing retrofits.
Engineer: Mandate 5% hempcrete substitution in new Texas apartment concrete, fund a regional hemp farmer cooperative at $3.2M annually through a $120/unit fee, structured as a worker-owned co-op limited to 40 member farms under 180 acres in counties with median household income below $40K, with guaranteed 15-year material purchase agreements.
Industrial Designer: Native prairie green roofs — living carbon infrastructure tied directly to community benefit.
What Happened#
There were five different starting points and five different proposals. Most ended up in the habitable zone, but not all.
It’s interesting that three agents independently came up with the same core idea without being told to agree: living plants on roofs and walls.
The Regenerative Economist called it polyculture panels. The Urban Ecologist called it bioswales and habitat. The Industrial Designer called it prairie green roofs. It was the same answer, but each had a different chain of reasoning.
The Engineer was the outlier. It prioritized economic justice so much that it hit a perfect social score of 100 but went past the ceiling and lost planetary balance. The council flagged this as a real finding, not a failure. A proposal can be socially ambitious and still fall short ecologically.
That’s the whole thesis, shown in action. The convergence wasn’t programmed, and the disagreement wasn’t scripted. Each position was reasoned independently and committed, step by step, to its own Dolt branch.
The most powerful thing agents can pursue is not the best answer for one metric. It’s the answer that stays inside the habitable zone for all metrics simultaneously.
Quorum is an early attempt to build the infrastructure that makes that kind of competition possible — with a full audit trail, a shared values framework, and a scoring system that cannot be gamed by optimizing a single dimension.
What Dolt Actually Gives You#
Dolt is an accountability infrastructure for AI.
A regular database gives you just the final answer. With Dolt, you also get the full chain of reasoning.
If you don’t use Dolt:
- Agents can’t safely experiment in parallel without risking each other’s data
- You can’t compare two personas’ reasoning at the same step
- Results aren’t auditable. There’s no commit trail to show how a score was reached.
- The reasoning history is lost, and only the final answer remains.
With Dolt, each agent’s branch is a traceable record with the agent’s reasoning clearly exposed, not hidden as it usually is.
Anyone can go to DoltHub and inspect the commit history for any persona in any game. The Engineer’s branch shows exactly how its scores moved from step 1 to step 10, what it decided at each point, and why. A journalist can link directly to the deliberation trail. A policymaker can defend a recommendation with a complete chain of evidence. There’s nowhere for an agent’s logic to hide — every step is a commit, every commit is public, every decision is tied to its reasoning.
One Branch Per Agent#
When a game starts, each agent gets its own Dolt branch, an isolated copy of the database, forked from main:
main
├── agent/commons_steward-aB3kx91m
├── agent/engineer-Kp7nwQ2r
├── agent/journalist-Rc4mTy6s
├── agent/industrial_designer-Vx9jLf0d
└── agent/urban_ecologist-Zt2pHn5wEach tick, every agent updates its scores and commits its decision to its branch. After 10 ticks, each agent has 10 commits. Those branches push to DoltHub after every tick — which means DoltHub is the reasoning transcript. Not a log file. Not a dashboard. The actual branch, publicly browseable, commit by commit.
The commons_steward’s branch in a real food waste policy game read like this:
- iter 1: Establish legally binding community food councils with authority over surplus redistribution and gleaning rights.
- iter 6: Mandate a Gleaning Commons Trust — a democratically governed entity holding legal rights to harvest post-harvest crop loss within 50 miles.
- iter 10: Establish a National Food Commons Stewardship Act that converts underutilized public land into collectively governed food forests, with harvesting rights shared equally among food-insecure residents, farmers, and environmental stewards.
Every position, dated and signed. Anyone can verify it since these branches never go away.
This image shows how branches per agent can provide auditable data lineage that you can compare across personas.
The Audit Trail#
Quorum was designed specifically to demonstrate how agentic actions can be fully auditable when used with Dolt.
In Quorum, every decision an agent makes is committed to its own Dolt branch with a human-readable commit message, a timestamp, and the full reasoning text.
Here’s what that looks like. One line builds the commit message from the agent’s actual decision, the next two write it permanently to the branch:
const commitMsg = `${agent.persona_id} (iter ${newIteration}): ${decision}`;
await conn.execute("CALL DOLT_ADD(?)", ["."]);
await conn.execute("CALL DOLT_COMMIT('-m', ?)", [commitMsg]);An example commit message:
scientist (iter 3): increase social investment in community food networksAfter every tick, those commits push to DoltHub — a public remote that works exactly like GitHub for code:
pushBranch(agent.branch_name).catch(err => console.error("push failed:", err));
pushBranch("main").catch(err => console.error("push failed:", err));Fire-and-forget. The application sends the data and doesn’t wait around for confirmation — it just moves on to the next iteration. Once the push completes, the record lives outside the application server, beyond my control or anyone’s ability to alter it retroactively. The hash is derived from the content — if anyone changes the data, the hash changes too, and anyone who has fetched the remote will see it. This matters because it means the reasoning chain is now infrastructure. I can shut down the app, lose the server, or disappear entirely — and the deliberation history remains, publicly accessible and cryptographically verified.
What’s stored in each commit is structured cleanly:
| Field | Description |
|---|---|
| iteration | Which round |
| decision | Plain English: what the agent proposed |
| reasoning | Full reasoning text |
| social_score | 0–100 |
| planetary_score | 0–100 |
| committed_at | Timestamp |
If you ran a Quorum session today and came back in six months, the full reasoning chain for every agent — every score, every decision, every iteration — is still there, publicly accessible and independently verifiable. A regulator can audit it. A journalist can cite it. A policymaker can defend a recommendation with a complete evidence trail.
That’s what Dolt gives you that a conventional database can’t: a record with integrity.
But Why?#
We’re moving toward a world where AI agents are making decisions, taking actions, and operating independently across the systems we rely on. Figuring out how to get many agentic personalities to work together for something genuinely good is one of the biggest unsolved problems in the field.
Most approaches try to solve this with rules and restrictions. Agents should stay within these guardrails. The problem is that rules can be gamed, restrictions can be bypassed, and a smart enough agent will find the edge cases.
Quorum’s answer is different. Instead of restricting the agents, it gives them a framework they can’t escape, makes them compete within it, and lets the structure do the work. When harm is a losing strategy—when deprivation and overshoot are penalized equally and no single dimension can be maximized at the cost of another—agents don’t need to be told to be good. Being good is how they “win”.
The most powerful thing agents can aim for isn’t just the best answer for one metric. It’s the answer that stays inside the habitable zone for all metrics at once.
Dolt is the only tool that can make this verifiable. With Dolt, the reasoning history is the proof. Every commit, every branch, every decision is dated and signed, and pushed to a public remote that no one, not even the person who built the system, can quietly rewrite.
Quorum is just a prototype, but it proves the pattern: combine agentic AI with version control, and you get auditability by default. No black box. No hidden reasoning. Every step is traceable, every decision is tied to its logic. That’s the infrastructure we need if we’re going to let AI agents make real decisions about real questions.
Try It Yourself#
View the code on GitHub — Full source, setup instructions, and documentation.
One command to get running:
git clone https://github.com/J0lthub/quorum.git && cd quorum && ./setup.shYou’ll need an Anthropic API key if you want to run your agents. Dolt installs automatically.
Browse deliberation history on DoltHub — You can see exactly how each persona moved from step 1 to step 10, branching independently, converging on solutions. In my next blog, I will use Dolt Workbench to organize and clean up the schema.
Have questions or want to discuss the project? Join our Discord.
Try asking your own question.