
A lot of people are hearing about Dolt for the first time via Beads, Gas Town, and now Wasteland. All three of these products are Steve Yegge creations. Beads manages agents’ tasks. Gas Town is the first working multi-agent orchestrator. Wasteland is a federation of Gas Towns around a single shared job board. Steve seems determined to drag software engineering into the multi-agent era.
Dolt is a critical piece of Steve’s multi-agent world. Dolt is the persistence layer for Beads, meaning agents in Steve’s products use Dolt to track their tasks. Why did Steve adopt Dolt for task persistence? It turns out Dolt is perfect as a multi-agent persistence layer. This article explains.
Multi-Agent#
Let’s first define multi-agent. Steve presents a good model for artificial intelligence (AI) adoption in software engineering. Software engineers progress up the stages as they get more comfortable with AI tools writing code for them.
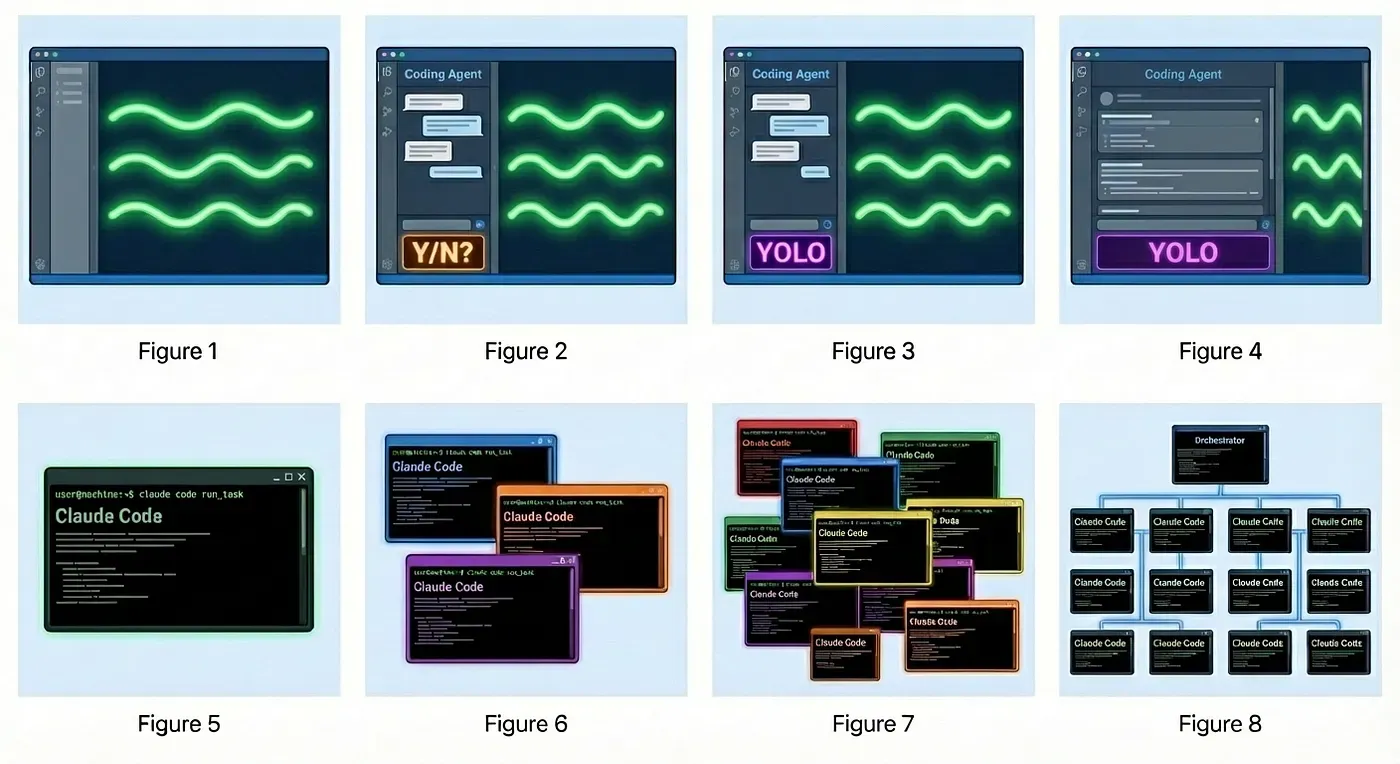
Stage 1: Zero or Near-Zero AI: maybe code completions, sometimes ask Chat questions.
Stage 2: Coding agent in IDE, permissions turned on. A narrow coding agent in a sidebar asks your permission to run tools.
Stage 3: Agent in IDE, YOLO mode: Trust goes up. You turn off permissions, agent gets wider.
Stage 4: In IDE, wide agent: Your agent gradually grows to fill the screen. Code is just for diffs.
Stage 5: CLI, single agent. YOLO. Diffs scroll by. You may or may not look at them.
Stage 6: CLI, multi-agent, YOLO. You regularly use 3 to 5 parallel instances. You are very fast.
Stage 7: 10+ agents, hand-managed. You are starting to push the limits of hand-management.
Stage 8: Building your own orchestrator. You are on the frontier, automating your workflow.
Anything stage 6 or greater is considered multi-agent. The end goal in this evolution is for you to become the foreman of a software development factory staffed by agents. Personally, I’m at stage 5, though next week I’m going to skip straight to stage 8 for a project I’ve been dreaming up.
Gas Town is Steve’s implementation of that vision and it works.
Anthropic is building multi-agent capabilities into Claude Code itself. Claude Code added tasks in late January, noting Beads as an inspiration. There are also Claude Code Sub Agents and Claude Code Agent Teams. These Claude features are more building blocks for you to assemble your own agent orchestrator. In contrast, Gas Town is very opinionated about the orchestration model complete with its own lingo: “the mayor is slinging work to a polecat.”
It’s fair to say that 2026 is shaping up to be the multi-agent year. I expect dozens of competing multi-agent orchestrators to launch. If you’re reading this, you may be building one yourself.
Agentic Memory#
In the single agent era, agentic memory was a nice-to-have. Your agent could resume where it left off or work for longer without interruption. As seen with Beads and Claude Code tasks, the most important thing for an agent to remember is what it is working on: its tasks.
Agentic memory is active area of research. What else should be persisted between sessions? Roles? Personalities? Lessons learned? We’re going to see more tools developed in this space.
In the multi-agent era, agentic memory becomes a necessity. To get many agents to work together, they all need to cooperate on some shared state, the minimum being a set of tasks to complete.
Multi-Agent Persistence#
Agentic memory requires persistence. Where do you store information for agents to recall as necessary?
Claude Code’s strategy is to persist all agent state in JSON files in the .claude directory. Users define some configuration in markdown files like AGENT.md.
$ tree -L 1 ~/.claude
/Users/timsehn/.claude
├── backups
├── cache
├── debug
├── downloads
├── file-history
├── history.jsonl
├── paste-cache
├── plans
├── plugins
├── policy-limits.json
├── projects
├── session-env
├── settings.json
├── shell-snapshots
├── stats-cache.json
├── statsig
├── telemetry
└── todosBeads takes a different approach. Beads models tasks as structured data instead of markdown or JSON. Steve noticed agents needed the ability to query and update their task graph, often needing to do so in a fine-grained manner as to not pollute their context. Steve first persisted tasks in SQLite with a sync mechanism to JSONL for sharing and auditing using Git. Tasks were better modeled as versioned, structured data. This approach worked fine for the single agent use case.
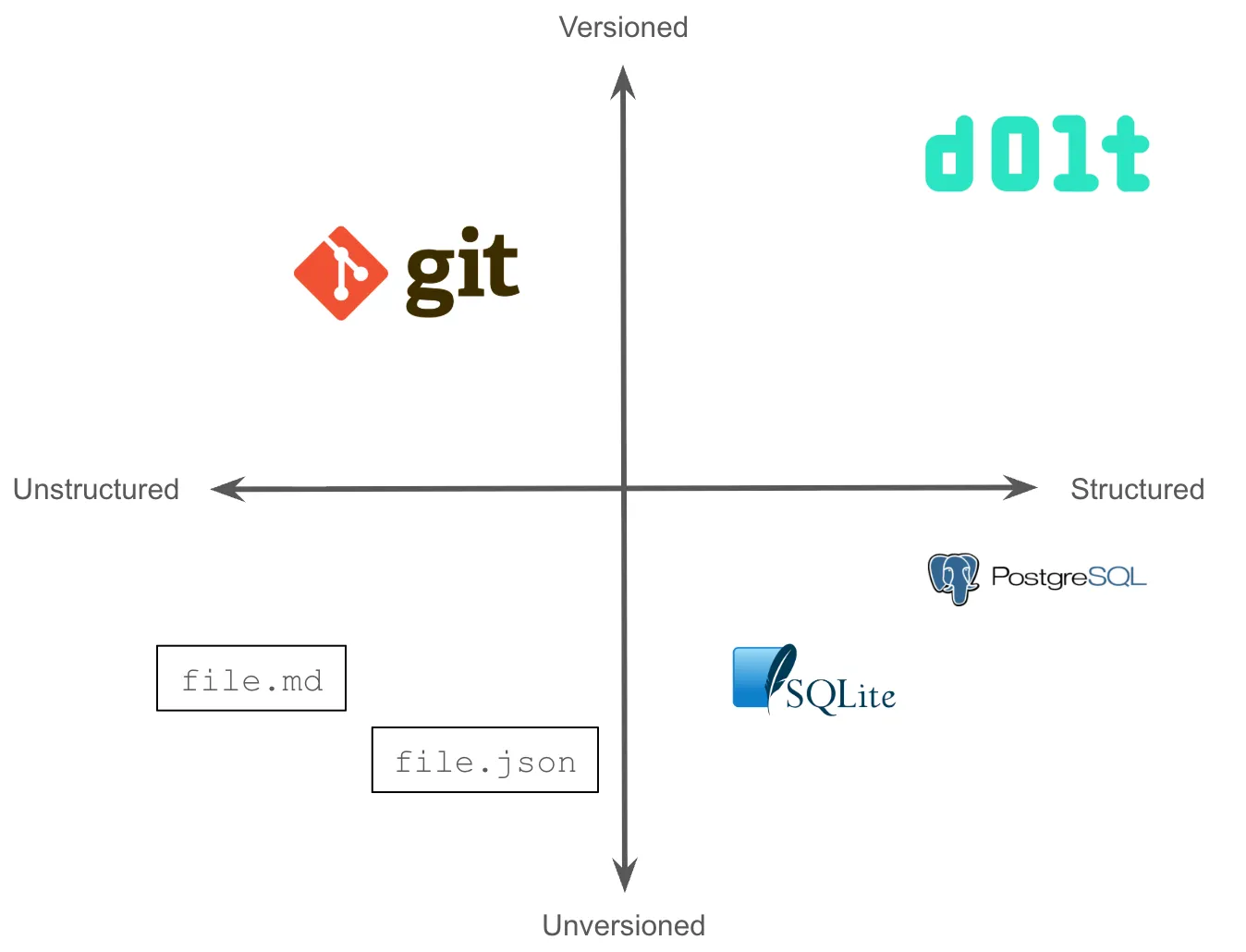
You can see a problem space starting to be defined. On the x-axis, you have a continuum from unstructured to structured data, like data traditionally stored in a SQLite or Postgres database. On the y-axis, you have unversioned to versioned data. Versioned files are stored in Git. Versioned structured data is stored in Dolt.
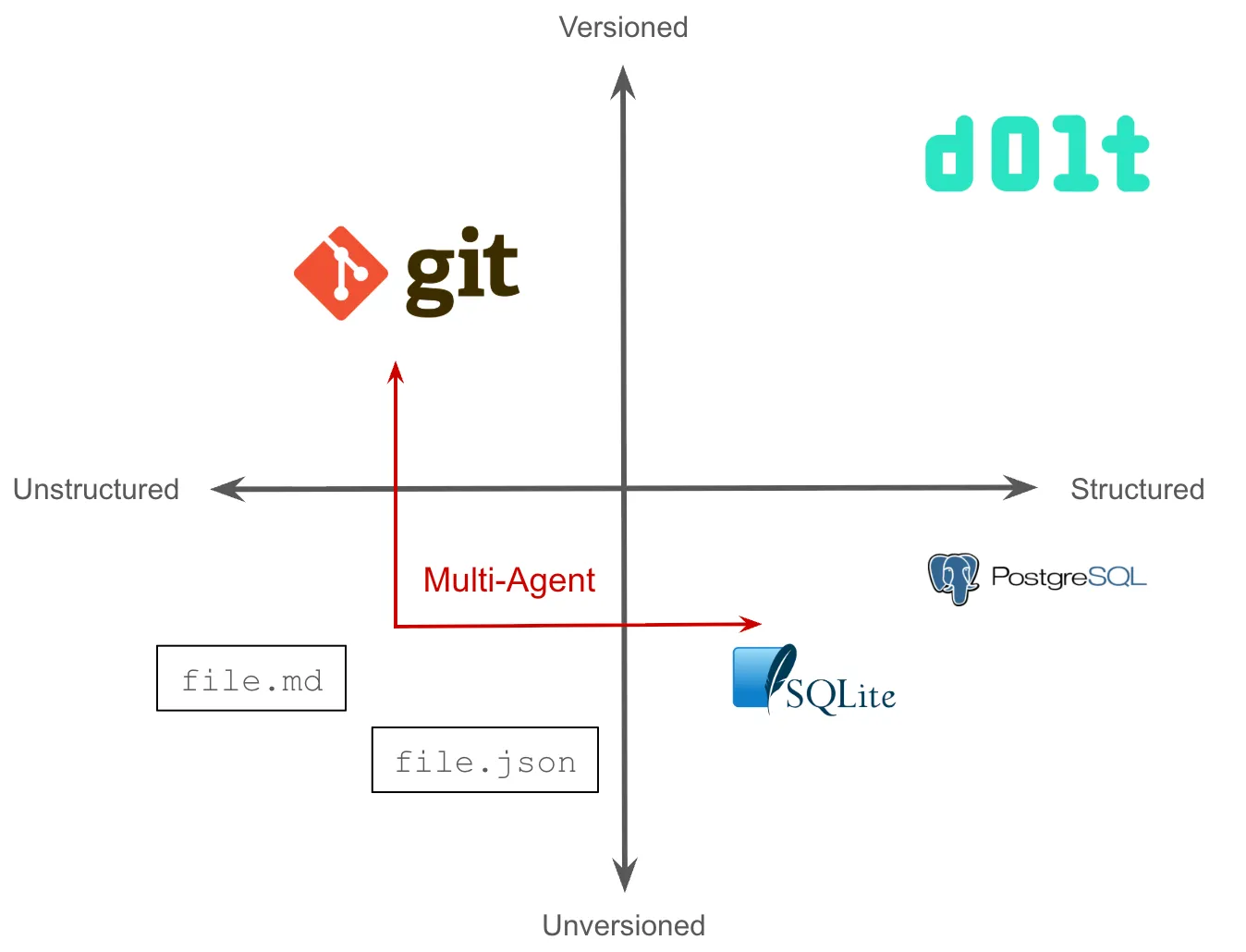
Enter Gas Town, our first multi-agent orchestrator. Gas Town uses Beads to coordinate tasks among many agents. With many agents reading and updating a single Beads database, concurrency became an issue. SQLite uses optimistic locking for multi-process concurrency, which means last write wins. You can get transactional concurrency if SQLite access is routed through a single process but this requires building and running a server. Postgres would be a better choice in this case. The many agents in Gas Town would stomp each other’s writes causing unrecoverable chaos.
In Gas Town, the ability to audit history also becomes important. Agent writes are what I call “semi-trusted”. Traditional database systems are designed for trusted writes. The only way to rollback an update is to manually apply the inverse SQL query or restore from a backup. Semi-trusted writes require versioning. For instance, without versioning, agents would attempt to mark a Bead as complete, only to see it had been deleted or updated by another agent. This event would cause the agent to get unrecoverably confused. Much like code in Git, versioning allows an agent more tools to debug this situation and continue working. If Beads are versioned, then the confused agent can look at the history of the Bead, see the commit message, and make a more informed decision about how to proceed.
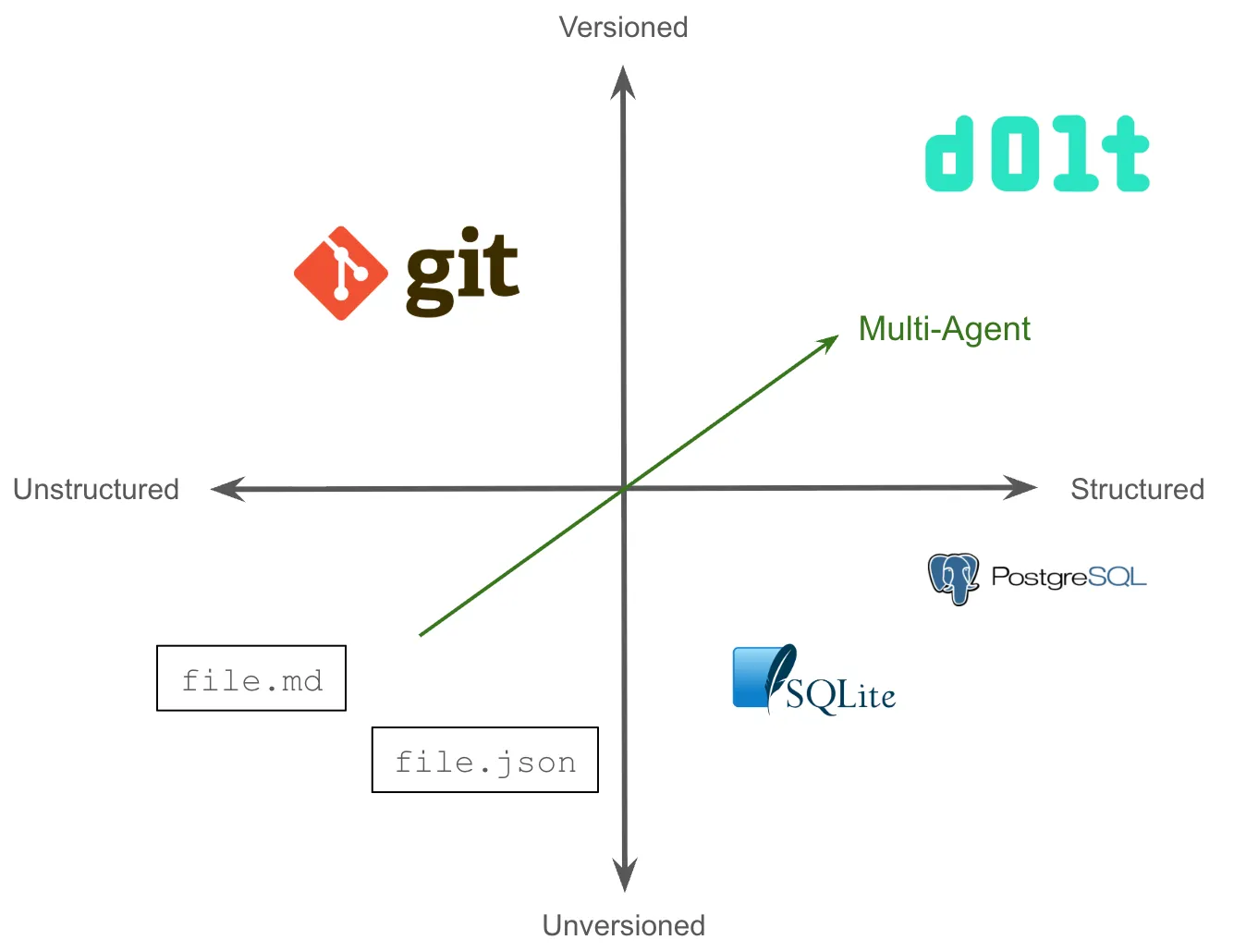
So as you can see, multi-agent pulls agent state from files in your agent directory into the versioned quadrant and the structured quadrant at the same time. Without Dolt, multi-agent use cases force you to choose between files in Git or an unversioned database like Postgres. In Beads, Steve tried to get both by building a syncing mechanism between SQLite and JSONL files in Git, but this approach proved too fragile to be workable.
Enter Dolt#
Dolt makes it so you don’t have to choose between versioned and structured. You can have both. Dolt provides Git-style versioning on a SQL database. You have the full query and concurrency management power of a database combined with all the features you know and love from Git: commits, branches, merges, diffs, conflicts, rebase, and tags to name a few.
Dolt is not new. The code is ten years old. We didn’t build Dolt anticipating AI. Dolt just happens to be the perfect database for multi-agent persistence and many other AI use cases.
Beads migrated to Dolt almost a month ago to support Gas Town’s multi-agent use case.
Does it Work?#
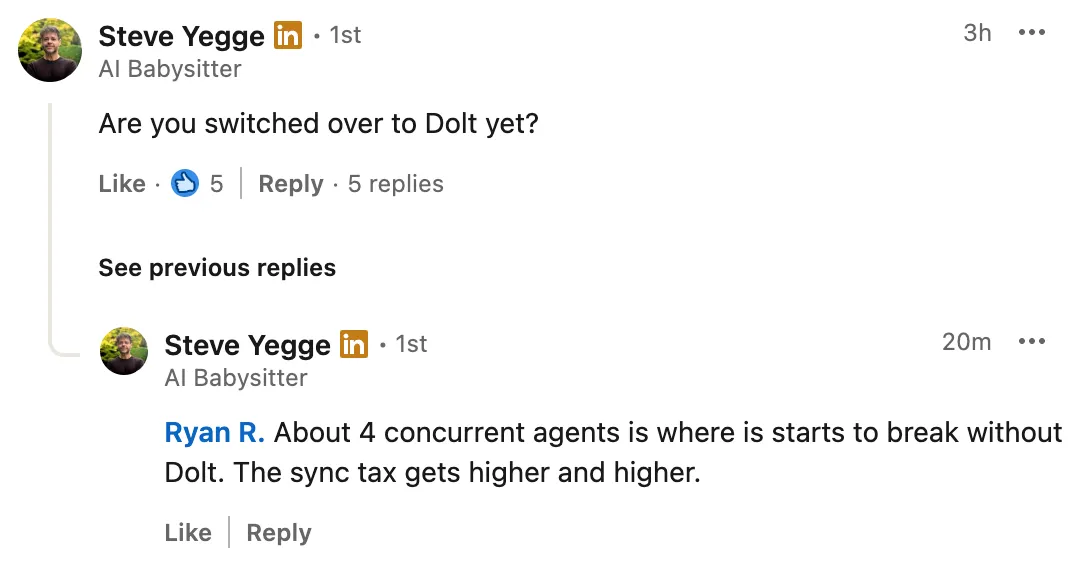
Yes. Reports are that Gas Town powered by Dolt allows ~160 agents to work concurrently on a single host. An upcoming Gas Town release, which uses Kubernetes to deploy on multiple hosts, has achieved ~600 agents working concurrently. Without Dolt, Gas Town struggled at more than four concurrent agents.
Beads and Gas Town are only scratching the surface of the versioning capabilities Dolt provides. History, audit, and diff are exposed directly to agents via Dolt. Beads uses unversioned tables for ephemeral Beads called Wisps. Beads uses rebase for history compression. The full power of branch and merge have not been integrated yet.
Conclusion#

The above captures the sentiment in the Gas Town Discord. All multi-agentic roads lead to Dolt. Gas Town is the proof. Building a multi-agent system? Come by our Discord and tell us about it. We’re happy to help.