
Here at DoltHub, we built the world’s first version-controlled SQL database: Dolt. What do version control and databases have to do with Artificial Intelligence (AI)? It turns out, a lot.
At first, we were skeptical about the AI revolution but then we discovered Claude Code. All of a sudden, Dolt became the database for agents. A little later, we decided Dolt is the database for AI. It says so right at the top of our homepage.
In 2025, we talked a lot about AI in this blog. As this pivotal year for AI comes to a close, let’s step back and survey the AI space and its impact on databases. This article will explain what AI is used for today, what it might be used for in the future, how these use cases effect databases, and finally conclude with some potential AI databases to consider.
What Can AI Do Today?#
AI stands for artificial intelligence. The big innovation in AI over the past few years is generative models. Generative models started with text. Now, generative image, audio, and video models are very good as well. An AI can generate realistic text, image, audio, and video output based on a simple prompt. Generative AI models are getting better quickly. The companies that make them, OpenAI and Anthropic, have become household names.
Generating content from text prompts is generally useful but a few specific use cases have emerged. Let’s dive into a select few of those in detail roughly ordered from oldest to newest.
Universal Similarity Search#
The universal similarity search use case has been around since the earliest generative models. A generative model can take an input, text, image, audio, or video, and summarize it into a fixed length vector (ie. series of numbers) called an embedding. The distance between two vector embeddings indicates how similar the two inputs are in the eyes of the model that generated the embeddings. Since the model exhibits a human-like understanding of the input, the similarity returned is what a human would identify as similar. Universal similarity search can be used directly in a number of applications like search and recommendations.
Universal similarity search is also useful for generating content or answers with a generative AI model using a process called Retrieval Augmented Generation or RAG. Generative models are trained on public data. So, in an enterprise setting, if you ask a generative model questions about private data the answer will likely be incomplete or wrong. RAG solves this problem. First, you index all your internal documents into vector embeddings using a generative model. Then, you use the same model to embed the user prompt. Then, by using similarity search between the user prompt and your indexed documents, you augment the prompt with the top N most similar documents. In theory, the generative model will now consider your private data when composing a response.
However, in practice, data sent in context effects the generative model differently than data used to train the model. If you’ve used a coding agent, you probably realized that too much or incorrect information in the context yields frustrating results. Data in the context receives hyper-focus from the model. The model assumes the data must be important. So, RAG flooding the model context with similar documents seems risky at best. We tried RAG internally for a blog article generator and the results were worse than without RAG. It’s not just us. The internet is not filled with many RAG success stories. I’m sure in some use cases, however, RAG is better than nothing. My intuition is that RAG use cases will switch to post-training using private data on open or licensed proprietary models.
Summarize#
Generative AI is very good at summarizing information. The model is trained on the entire internet’s worth of data and then some. A user creates a prompt requesting some piece of information in some style. The model generates a bespoke summary of the information in the model that answers the user’s prompt.
The main consumer use case for this is AI chat with the main brand being OpenAI’s ChatGPT. Effectively, this use case is a better web search for many queries. As many of you know, Google search has long been one of the most profitable and defensible businesses on the internet. So, a new challenger is exciting. Anecdotally, since ChatGPT was released in 2023, search traffic to dolthub.com is down about 50%. We believe these search queries have been replaced by ChatGPT and other AI chat queries.

Since ChatGPT was released in 2023, there have been many improvements to these models. The models hallucinate less and produce more factually accurate information. The models are better at identifying errors or anomalies in large amounts of information. In short, the models are smarter and will likely continue to get smarter. These improvements have opened up research and editing use cases traditionally served by clerks or analysts.
Write Code#
Generative AI write summaries meant for human consumption. These summaries are not authoritative writes to the system of record. For AI to actually do “real work”, AI must make writes to the system of record. Enter AI coding, the first AI use case where AI was reliably writing to the system of record.
AI coding came on slowly than all at once. In 2024, AI-assisted coding was popularized by the Integrated Development Environment (IDE) Cursor. Cursor bolted an AI connected chat window onto the side of Visual Studio Code, a popular open source IDE. To get the AI to write code, you instructed it to do tasks via the chat window, similar to a conversation with ChatGPT. I found this process very slow and frustrating but others claim it increased their productivity.
Then in Q2 2025, agent-based AI coding burst onto the scene. First, Cursor added agent-mode. Then, a command line tool called Claude Code was released by Anthropic. Coding agents looped on a prompt ensuring the code the agent produced compiled and passed tests. This simple change meant that a coding agent could work for minutes in the background and reliably produce production code for small to medium sized tasks. Coding agents work and reliably make writes to the system of record opening up the possibility for the automation of many more knowledge work tasks.
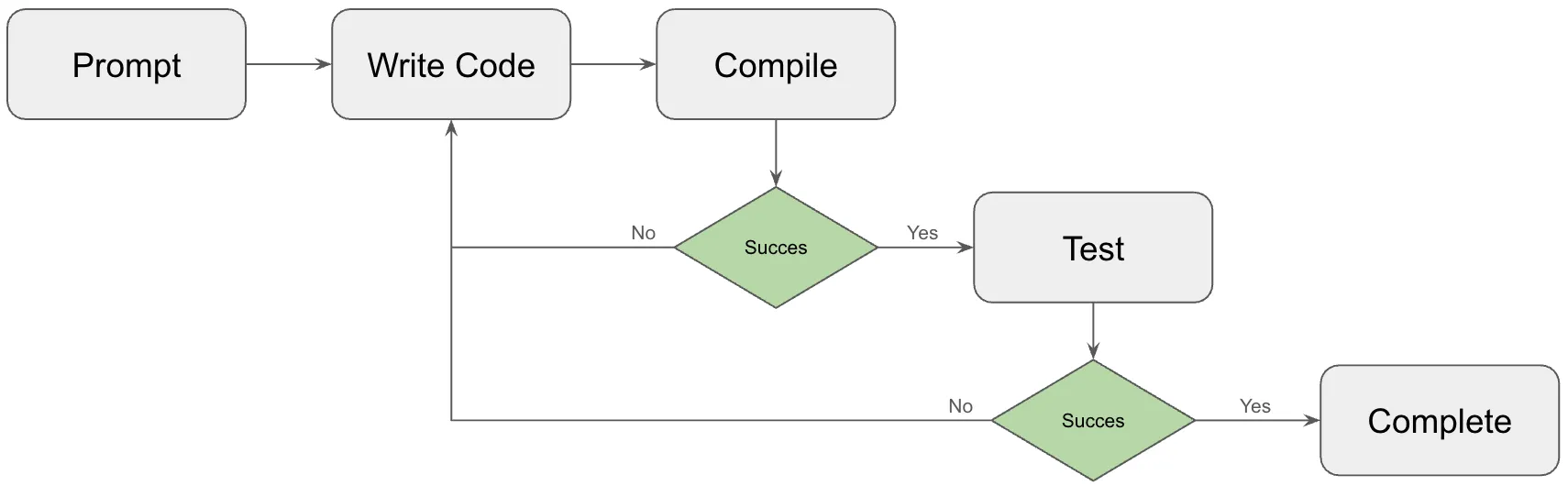
Existing version control systems for code facilitated agentic coding. Version control allowed agents to work in parallel to their human operators. Version control allowed an agent’s code to be reviewed. If the agent’s code was wrong in some way, the code could be easily discarded or rolled back using version control.
In parallel to Cursor tackling AI-assisted coding, a parallel category of tools called App Builders was introduced. App Builders use AI to build full stack websites or mobile applications. Popular App Builders include Replit, Vercel v0, and Lovable. App builders not only write code, but also handle deployment and operations, making them very popular for non-coders and prototypes. Being full stack, App Builders generally include a database which is directly relevant to this article.
Self-Driving#
Outside the realm of information technology, AI also has a profound physical world application. Cars can drive themselves! Self-driving cars use generative AI to predict the next few seconds of the surrounding environment and react accordingly.
DoltHub headquarters is based in Santa Monica and we are one of the early Waymo service locations. Tesla’s have a self-driving option as well and they are rolling out a Waymo-like service in Austin, Texas. Self-driving cars are comfortable and safe. In the next few years, I suspect we will see self-driving cars in most cities.

What Will AI Do Next?#
Based on what AI is doing already, let’s speculate on what we will see AI do next.
Cursor For Everything#
Based on the success of AI-assisted coding in tools like Cursor, we are going to start to see Cursor for Everything. Coding started with this interface. I think most other AI automation will start with this interface as well. Google has already added a Cursor-like UI to Google Docs and Google Sheets. I suspect most applications are going to have an AI-assisted mode powered by a chat window on the side.
Instead of manually performing tasks in an application’s user interface, a user will instruct an AI to do a task for them through the chat window, iterate, and review the results before committing the final result to the system of record. The main window of the application will look and work the same as usual with some slight tweaks to expose what the AI is doing or has done.
There are some challenges to be solved with version control and automated verification for these applications to work as well as Cursor. What did the AI do? Is it correct? How do I review? A database for AI could help solve some of these challenges.
Agents For Everything#
Just as chat-assisted coding morphed into full agent mode, I think you’re going to see other specialized agents capable of performing other small- to medium-sized business tasks. Ideal tasks have verifiably correct output such that an agent can loop until it gets the correct result instead of needing human-in-the-loop, “Cursor for Everything” applications. Again, having a version-controlled system of record so that an agent’s changes can be done in isolation, audited, rolled back, and reviewed becomes critical.
Once we get agents for more business tasks, we’re going to get multi-agent systems. Specialized agents are going to perform parts of most business tasks and whole business workflows are going to have tasks passed between specialized agents. The goal would be an agentic closed system where humans just watch work get completed and react to anomalies. For Dolt, I could imagine an agentic SQL tester finding Dolt bugs and creating issues on GitHub. Another testing agent would create a skipped test for the bug and get it reviewed by the code review agent. Finally, a coding agent would pick up the task, fix the bug, and again get it reviewed by the code review agent. Once complete the change would be merged and a Dolt release agent would ship the change to the world. This could all happen without a human ever reviewing any code given high enough code quality.
Advanced Robotics#
Beyond self driving we’re going to see a robotics revolution. Generative AI has provided the “vision” and “brain”. Cameras, sensors, batteries, and electric motors have become small and cheap enough to open up many new robotics use cases. The use case capturing most people’s imagination are humanoid robots. I’m sure we’ll see other more specialized robots, especially in the warehouse and factory settings, before we have an in home robot to do our dishes.
What Does AI Mean For Databases?#
Now that we have gone through some AI use cases, let’s examine what this innovation in AI means for databases. What new database features are needed to support AI use cases? What existing database features become more important? What new types of data need to be persisted? What query interfaces are needed?
Training Data#
Storing training data in databases is probably more applicable for traditional machine learning rather than generative AI though there are interesting generative AI datasets. Traditional machine learning relies on human or machine generated labels to produce a model. Generative AI does not. Traditional training data is usually somewhat structured. The raw data is usually stored in a Online Analytics Processing (OLAP) database with specific training datasets being pulled to feature stores. Traditional machine learning data can benefit from new database features like version control as we’ve seen here at DoltHub via Flock Safety. Flock Safety stores all their vision and audio training data in Dolt and leverages Dolt’s version control features for model reproducibility, explainability and collaboration.
Modern generative AI pre-training requires a massive training corpus, basically the entire internet plus any other quality data you can get. For large language models (LLMs), the data is raw text. These models split the data into training and test and then optimize a loss function, continually tuning the model. The last few years have been dedicated to scaling out pre-training data and compute, producing ever more effective models. From a database perspective, this raw text must be stored but the query requirements don’t go far beyond “give me all the data”. The data is also not highly curated. The more data the better. Thus, this training data is likely 99% appends. 1% updates and deletes for removing obvious garbage. Thus, I suspect training data for large language models sits comfortably in cloud storage like AWS S3 or Google Cloud Storage. When it’s needed, it’s pulled in bulk reads.
For generative AI, there are interesting curated post-training and evaluation datasets. These datasets are similar to traditional machine learning datasets with human curation and labels. I’m not very familiar with this space but a few prospective Dolt users have been interested in versioning this data for model reproducibility, explainability, and collaboration. I’m eager to learn about this space so if you work with this data, please come by our Discord and educate me.
Vectors#
Vector databases were hot in 2024. Specialized vector database like Pinecone and Milvus were gaining traction and almost all database offerings were launching vector support. Even Dolt launched version controlled vector support in early 2025. Vectors in databases enables universal similarity search and retrieval augmented generation (RAG). A vector database must both store vectors and be able to calculate the distance between them quickly usually using vector indexes. Vector indexes are a non-trivial technical problem so the trade offs each database offering made is interesting. Vector support seems like table stakes for a database looking to support AI use cases. Though, as mentioned above, the popularity of RAG seems to be waning.
More Writes#
This analysis is about to get a bit more meta as I think through the new data requirements in a world where generative AI and agents are commonplace. We’re really at the beginning of a new AI technology cycle so predictions instead of hard facts rule the day. There are a number of factors stemming from generative AI that will result in more writes to databases.
In general, data becomes more useful because AI can find patterns and anomalies in data that humans can’t. This will result in more data stored. This data will likely be mostly append only, semi-structured, and read in big batches. This makes OLAP solutions attractive. Expect your company’s Snowflake and Databricks bills to go up.
Context is the term for all the information you send to an LLM to generate a response. Context is important to understanding why the LLM produced a certain response. Agents produce multiple round trips to an LLM each producing context. Context is like an agent’s stack trace. All this context should be stored resulting in much more data being written. It’s odd to me that better storage for and interfaces to context don’t already exist. This data is mostly text but could benefit from features like rewind, forking, and merging as both user-facing features or for agent’s themselves.
With agents becoming more commonplace, currently human-scale write workloads will become machine-scale write workloads. This may pose some challenges for multi-view concurrency control (MVCC), the current technology for managing concurrent writes to databases. Agentic writes will be at machine-scale, longer duration, large batch, and may require review. Potentially, MVCC isn’t enough. Any conflicting writes in MVCC are rolled back making frequent, long duration, large batch writes problematic. More advanced concurrency control techniques that minimize or manage conflicting writes will be necessary.
App Builders#
As mentioned above, App Builders need a database for the App AI is building for you. Neon is the early leader in this market. Neon is the default database for both Replit and Vercel V0. Neon’s scale to zero and versioning capabilities made it the early leader. Neon deploys a standard Postgres database on top of a copy-on-write filesystem. The compute can be detached when not being used allowing the user to only pay for storage. The copy-on-write filesystem allows for convenient forking of database data, allowing the App Builder to build on a separate copy while the main application continues to operate as normal.
App builders seem like an obvious use case for a fully version-controlled database. Full version control would enable multiple users to build features on many branches. Rollback to any point in the past would be convenient. The AI could inspect database diffs to debug its mistakes. Databases changes could be reviewed along with code changes.
Structured Data#
For the agents for everything use case, agents could be making writes not only through APIs but also directly to databases. In this case, the more verifiable the result, the more reliable agentic writes will be. Structured data with schema will be preferred over unstructured, document-style data as data shape constraints can be enforced at write time. Free form documents lack the constraints necessary to serve agentic writes. Any constraints would be enforced in APIs. Thus, I see traditional SQL databases regaining some popularity in the AI database space.
Data Testing#
Agents need tests. Agents perform better with multiple layers of verification as evidenced by the coding use case. Data testing and quality control becomes more important for AI databases. Data testing has traditionally lived outside of the database itself. Rules on the shape of the data were enforced by the schema and constraints. Tooling in this space could shift as agents require more data testing tools.
New Interfaces#
Will AI require different interfaces? Model Context Protocol (MCP) exposes well defined tools to an LLM in order to perform specific tasks. Databases could directly support MCP interfaces in concert with traditional interfaces like SQL. As we learn more about which interfaces AI operates on more effectively, I suspect innovation in this space.
Permissions#
AI reads and writes may require different permissions compared to traditional database access. If an AI is sending context to an external LLM provider like is common today, should the AI be restricted from reading personally identifiable information to prevent data exfiltration? Perhaps each agent or agent type will get its own identity and this identity will cascade down to permissions at the database layer? Are current database permissions models expressive enough? At least in SQL, the grants and privileges system is extremely expressive. I think with the proper identity that system will suffice.
Isolation#
Related to permissions is isolation. You may not want an agent anywhere near the production copy of your data. You may want agents operating on copies, physically siloed from your production data to prevent any chance of mistake. For read heavy workflows, agents may generate suboptimal query patterns so sharing a physical resource with agentic workflows may be problematic. Write isolation is a desirable property for agentic writes but with traditional database systems, merging isolated writes back into production is difficult. Decentralized version control, like Git does for files, can facilitate merges of isolated writes.
Rollback#
With more frequent writes through potentially error prone agentic processes, the ability to rollback changes becomes necessary. It already feels anachronistic that operator error on your database can cause data loss or hours of downtime while you restore from an offline backup. Moreover, the need to rollback individual changes while preserving others will become more important as write throughput increases. Agents will experiment with writes and roll them back if they do not pass verification much like is done with agents writing source code today.
Audit#
Lastly, some classes of agentic writes will require human review and approval of changes. A human review workflow necessarily requires an AI database to have version control features in order to scale past a handful of concurrent changes. Branched writes, diff and merge become essential.
Moreover, once changes are accepted, audit becomes an important function for human operators of the system. What changed? What agent did this? When? Why? There is no human to ask for more context so the system of record must preserve more metadata about a change. Audit in databases has traditionally been accomplished using a technique called slowly changing dimension. However, version control systems have audit as a first class entity in the system. Version controlled databases obviate the need for slowly changing dimension.
AI Needs Version Control#
As I walked through what AI means for databases, you may have sensed a theme: AI needs version control. Surely, the creators of Dolt, the world’s only version controlled SQL database would believe that. But it’s not just us. The founding engineers at Cursor think so. The UC Berkeley computer science department thinks so. Andrej Karpathy, one of the leading thinkers in AI, thinks so.
In order for AI to extend to domains beyond code, AI needs to be operating on version-controlled systems. Code is stored in files. The rest of our data is stored in databases. AI requires version-controlled databases.
Timeline#
Perhaps you prefer a more of a chronological view of the AI database space covering what I’ve discussed in this article? Here you are.
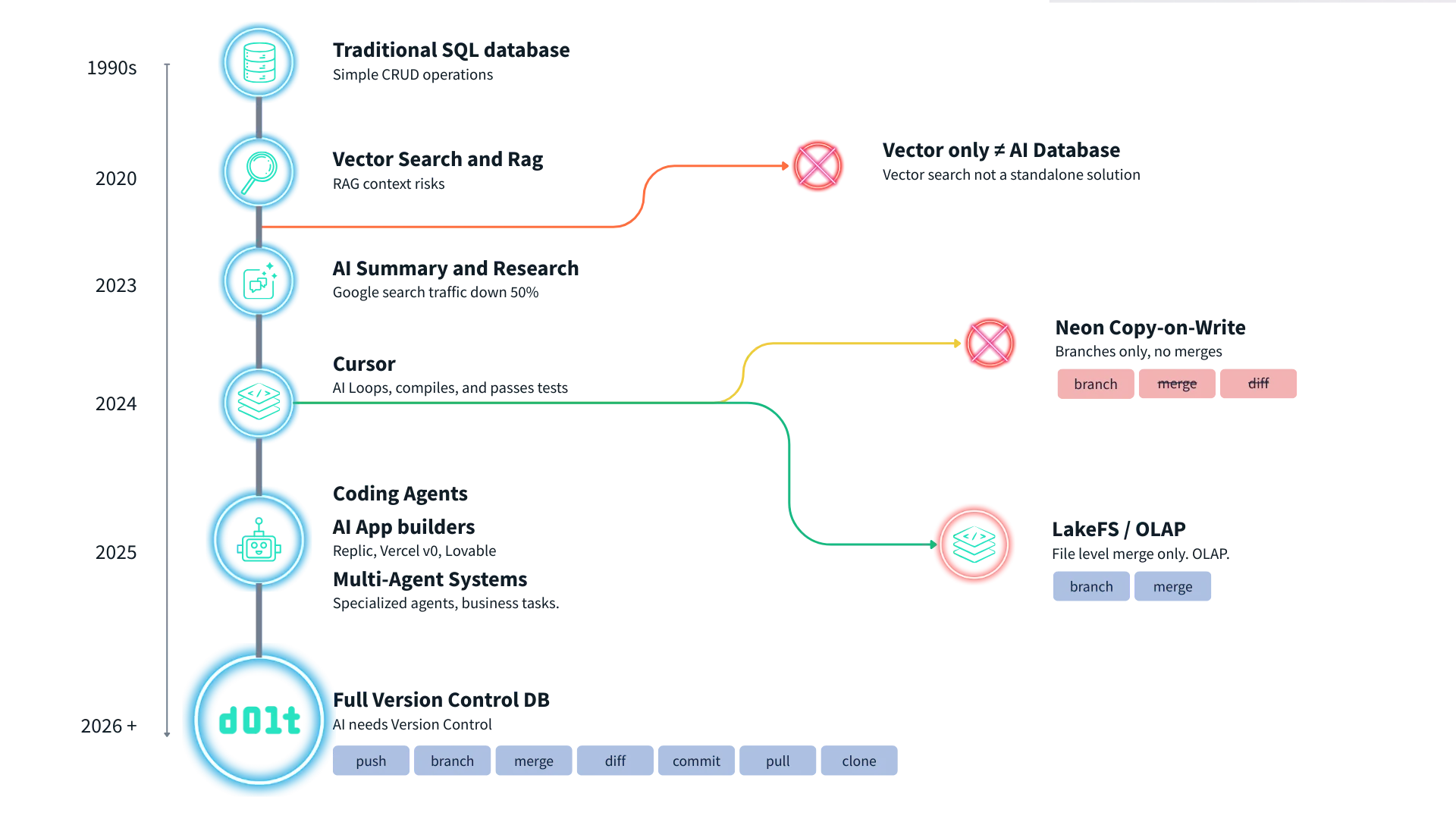
Products#
Now, let’s review the product options available today that could be AI databases. I focus on open source, free options.
Vector Databases#
Vector search used to be the domain of specialized databases. But now, almost every database supports vector search, including Dolt with version-controlled vectors. Moreover, I predict vector search won’t be a very important aspect of AI systems moving forward so I’m not going to dive deep into vector database solutions. However if you are looking for a vector database. check out Milvus, Weaviate, and Qdrant.
Version-Controlled Databases#
Now, let’s focus on version-controlled databases. I believe there will be more entrants in this space over time with a version-controlled option in every database category. Right now, LakeFS offers the only version-controlled OLAP database, and version control support is somewhat limited. Neon and Dolt are available for OLTP workloads. Again, Neon version control support is limited.

LakeFS#
- Tagline
- Scalable Data Version Control
- Initial Release
- August 2020
- GitHub
- https://github.com/treeverse/lakeFS
- SQL Flavor
- Apache Hive, Spark SQL
LakeFS is a version control extension for data lakes. It sits on top of many open formats like Parquet or CSV and adds version control functionality to those formats. You get SQL via Apache Hive or Spark SQL.
LakeFS supports branches and merges. LakeFS branches employ “zero copy branching”. LakeFS stores a pointer to a commit and then stores a set of uncommitted changes. It’s not clear from the documentation how these changes are stored. Given other documentation, I suspect a new version of any changed file is stored, meaning structural sharing is done at the unchanged file level.
Merge is handled at the file level, which in these formats is more like a table. Files in data lakes can be hundreds of Gigabytes. Conflict resolution is a simple take ours or take theirs at the file level.
Diff between branches is supported via the Iceberg plugin.
Neon#
- Tagline
- Serverless Postgres
- Initial Release
- June 2021
- GitHub
- https://github.com/neondatabase/neon
- SQL Flavor
- Postgres
Neon is a very popular open source Postgres variant. Neon separates storage and compute and substitutes the PostgreSQL storage layer by redistributing data across a cluster of nodes on a copy-on-write filesystem. Neon is the default database for the popular App Builders, Replit and Vercel.
Neon claims to support branches but there is no mention of merges in their branch documentation. All the text and visuals suggest branches are point in time copies and are not designed to merged. Diff between branches is not supported.
Dolt#
- Tagline
- Git for Data
- Initial Release
- August 2019
- GitHub
- https://github.com/dolthub/dolt
- SQL Flavor
- MySQL, Postgres (beta)
Dolt is true database version control. Dolt implements the Git model at the database storage layer using a novel data structure called a Prolly Tree. This allows for fine-grained diff an merge of table data while maintaining OLTP query performance.
While Neon claims to have branches, Neon’s branches are really forks. Dolt is the only database with all the version control features you know from Git: branch, merge, diff, push, pull, and clone. These features are essential for an AI database.
Dolt wasn’t built for AI. The code is ten years old. Dolt is older than the transformer, the fundamental building block of generative AI. It just so happens that AI needs Dolt’s features to reach its full potential.
Interested in learning more? Come by our Discord and I’d be happy to give you a demo.