
Arguably the most important design decision in a database is one that most users probably never think about: how your data is actually stored on disk.
On one hand, the storage format doesn’t matter to the user because it’s completely abstracted away. The entire purpose of a database, especially one with a declarative interface like SQL, is that the user doesn’t have to think about how their data is stored. They don’t have the think about how the engine resolves their queries. It simply does.
But on the other hand, the storage format used by a database matters more than anything else, because it dictates what operations can be done efficiently, and even what operations can be done at all.
Take Dolt. Dolt is the world’s first version controlled SQL database: you can clone, branch, merge, and push, just like Git. And the reason that’s possible is because of Dolt’s unique data structures in our storage layer.
As part of our approach, Dolt stores your data in content-addressable chunks. This is the same strategy that Git uses, and it allows for things like structural sharing: two tables with similar data can reuse chunks, reducing the total storage space. It’s what allows Dolt to store every version of your db simultaneously.
We’ve written in the past about how Dolt divides your tables into chunks. Here’s a visual representation:

In this diagram, we see how tables are trees, every table row is stored in a leaf node, and every node is a chunk. But it doesn’t explain what a chunk actually looks like on disk. And it turns out that how data is structured within a chunk is just as important as the chunking itself. So let’s zoom in on a single leaf chunk to understand what those bytes actually mean.
Suppose we have a table that looks like this:
| Employee ID | Name | Title |
|---|---|---|
| 1 | Tim | Founder/CEO |
| 2 | Brian | Founder |
| 3 | Aaron | Founder |
| 4 | Nick | Engineer |
Dolt is a row-oriented database, which means that it stores tables as a series of rows. This is different from a column-oriented database, where tables are stored as a series of columns. There’s some nuances and interesting trade-offs between the two that are outside the scope of this blog post, but the important takeaway is that a given row always stores its elements together in the same chunk. You can imagine that each chunk is just one or more rows concatenated together, and a row is just all of its cell values concatenated together.1
Inline Encoding#
The simplest approach is to just take the raw values and put them directly in the chunk. If we do this, we say that the values are Inline Encoded. For the above table, we can imagine that the first chunk might look like this:
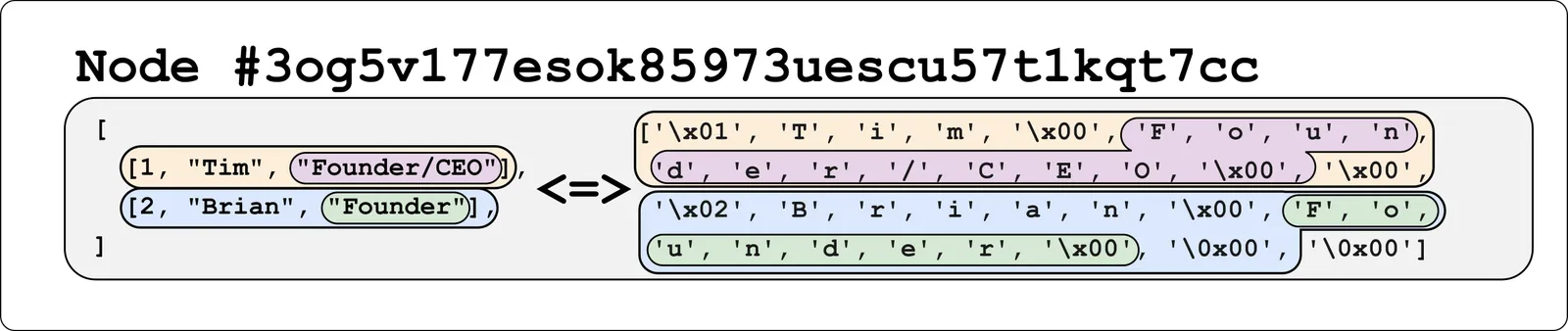
This system works great when the amount of data per row is small. But if we use this to store longer strings, we start to run into some issues, since more of the table data will be made up of these large strings. This impacts performance in several ways:
- We can fit fewer rows in each chunk, and tree will consist of more chunks (and with have more levels).
- We have to load the entire chunk in order to access any of the data in it. For non-string operations, most of the data is not useful.
Imagine we just want to SELECT id FROM t. This would require loading every row, which means it also requires loading every string, even though we don’t need them for the query.
And what happens if a string is so large we can’t fit it in a single chunk?
In cases like this, it would be really nice to not have to store the entire string in the chunk. We want to store it somewhere else. And in Dolt’s case, that “somewhere else” means “one or more separate chunks that we only load if we need to.”
Address Encoding#
Because the storage is content-addressed, every chunk can be loaded if you know its hash. So instead of storing the string in the table, we store the string’s hash in the table. Dolt hashes are always 20 bytes long, so it might look like this:

We call these strings Address Encoded. With address encoding, every string uses exactly 20 bytes of space in the chunk, while raw string data exists in a separate chunk. This uses more total space, but allows the table chunks to be loaded without incurring the cost of loading the raw strings. Plus, if the same string is used in multiple places, we only have to store it once. This means that datasets with duplicate string values may actually use less total space than an equivalent table with inline encoding.
Currently, Dolt defines encodings on a per-column basis, based on the table schema. “Small” columns (CHAR, VARCHAR, BINARY, and VARBINARY) use inline encoding, while “large” columns (TEXT, LONGTEXT, BLOB, and LONGBLOB) use address encoding.
But there’s a catch…#
There’s a tradeoff in using address encoding. While inline encoding is ill-suited for large strings, address encoding is ill-suited for small strings. The worst possible case for an address encoded column is if every value in the column is shorter than 20 bytes. If that happens:
- The table chunks will be larger with address encoding than they would be inline encoding
- The database will require more chunks than inline encoding, in order to store each string in its own chunk.
- Address ancoded columns have limitations when used as an index, since the engine will need to load a chunk each time it does a comparison.
- All operations that need one of these strings will need to perform an additional chunk lookup per-string.
There’s no upside here. This is all bad. The only way to avoid it is to use one of the column types that uses inline encoding, but then you’re putting a limit on the length of strings you can store. You have to make this decision up front, and if you decide to change your table schema later, you’ll have to rewrite every row in your table to use the new encoding.
We’re not thrilled with this. So we fixed it to get the best of both worlds.
Adaptive Encoding#
Postgres calls this feature TOAST (The Oversized-Attribute Storage Technique), but we think that name isn’t very descriptive, so we prefer to call it Adaptive Encoding, and we’re adding it to Dolt as an alternate format of encoding values in tables.
Adaptive Encoding is conceptually simple:
- Allow both inline encoding and address encoding to exist in the same column, with a tag to distinguish them.
- The engine can decide when updating a row what encoding should be used for text values.
But implementing it has some tricky bits. The main one is preserving history independence, a critical property of Dolt. It’s the idea that two tables that contain the same data should have the exact same encoding, regardless of the sequence of operations that led to that state. This means that the decision of whether to store a string inline or by address needs to be purely a function of the current state of the table.
Dolt accomplishes this by looking at the size of each value in a row, whenever any of the columns in that row are updated. These sizes are then used to determine which values should be inlined, and which values should be stored as addresses. Then, the whole row gets written with the proper encoding.
Adaptive encoding values always begin with a tag. For inline values, this tag is 0. For address values, this size is the size of the string pointed to by the address. This means in either case, Dolt can determine the length of the string simply by parsing the table chunk, without needing to resolve the address of address-encoded strings. Knowing the size without needing to load the string is critical, because it means that Dolt can use those sizes to consistently determine which columns need to be inlined and which columns need to be stored in their own chunks.
So let’s return to the previous example with the large biography strings, but this time use adaptive encoding to store a combination of large and small strings. It would look something like this:

The green value starts with 0xf1 0xa2, which is the SQLite variable length encoding for 402, the length of the string. The next 20 bytes are the content address.
The full impact of this new strategy can be seen in Doltgres, our in-beta Postgres-flavored Dolt. We’re switching Doltgres to use adaptive encoding by default for all TEXT and BLOB column types.
For now, regular-flavor Dolt will continue to use the original encoding strategy in order to preserve compatibility with older Dolt servers and older databases. This means Dolt will continue to use inline encoding for CHAR and BINARY and address encoding for TEXT and BLOB. We plan to add the ability for Dolt users to configure this in a future release, but we’re still working on the user experience. If you’re using Dolt in a way that would benefit from adapative encoding, drop us a line.
That said, even though Dolt isn’t currently changing how it stores values, it still benefits from this change because it allows us to use adaptive encoding within the engine.
Improving the Engine#
Dolt’s SQL engine is go-mysql-server, a pure Golang implementation of the MySQL dialect. While we created GMS specifically for use with Dolt, it’s agnostic to the underlying storage and can be used with other storage options.
Previously, when Dolt read rows from a table that used address encoding, it would need to resolve the addresses and fetch the the string chunks in order to return the row to GMS. Usually, the engine would only request the columns it actually needed, but correctly determining whether a value is “needed” can be tricky, especially if that value later got passed back to Dolt instead of being displayed to the caller. For example, consider this query to update a simple integer column in a table:
CREATE TABLE exam_scores (student_id INT PRIMARY KEY, score INT, essay TEXT);
-- Populate the table here
-- Then give everyone a perfect score
UPDATE TABLE exam_scores SET score = 100;The table has a TEXT column, but the query doesn’t read it and doesn’t modify it. So we would expect the text column to have no performance impact on the query result, right?
Unfortunately, it doesn’t quite work that way. GMS updates rows by computing the new value for the entire row and passing it back to the storage layer. This meant that in practice, Dolt would load the entire text value and pass it to GMS. Then GMS would pass it back as part of the new row, where Dolt would re-encode it.
But we can skip all that by making the engine aware of adaptive encoding. Instead of expecting the storage layer to always return a string, GMS could accept some representative value. We call these “Wrapped Values”, and its an interface that Dolt’s adaptive encoding implements. If the engine ends up needing the full value, it can ask the storage layer to “unwrap” it and return the underlying data. But otherwise, the engine can simply pass the wrapped value back to the storage layer.
This means the engine benefits from adaptive encoding even when the underlying table doesn’t: When Dolt encounters an address encoded value in a table, it can effectively convert it to the adaptive encoding and pass it to the engine without needing to fully deserialize the original string. The full string will get fetched if and only if the engine actually requires it for a computation or needs to return it in a query result.
The effects of this are most strongly seen when updating tables that contain lots of string data:
dolt init && dolt sql-server&
python <<PYTHON
import pymysql, random
db = pymysql.connect(unix_socket="/tmp/mysql.sock", user="root", database="scores_db")
cur = db.cursor()
cur.execute("CREATE TABLE exam_scores (student_id INT PRIMARY KEY, score INT, essay TEXT);")
ROWS = 10000
STRING_LENGTH = 10000
def make_string():
return ''.join((random.choice(string.ascii_lowercase) for j in range(STRING_LENGTH)))
cur.executemany("insert into test values (%s, %s, %s);", ((i, 0, make_string()) for i in range(ROWS)))
PYTHON
time mysql -h 127.0.0.1 -P 3306 scores_db -u root -e "UPDATE test SET score = 100;"
# Before adaptive encoding (commit 5fdf62df2f):
# 0.00s user 0.01s system 4% cpu 0.267 total
# After adaptive encoding (commit ce44582b3d):
# 0.01s user 0.01s system 26% cpu 0.061 totalLess time doing disk IO means faster queries.
tl;dr#
- Doltgres (Postgres-flavored Dolt) now uses adaptive encoding for text and binary columns, allowing for efficient handling of both small and large strings.
- Regular Dolt still uses either inline encoding or address encoding, depending on the column type. In a future release, users will be able to configure this.
- Despite Dolt not using adaptive encoding in its storage, we can still use it to improve performance of queries on
TEXTandBLOBcolumns.
The End#
That’s all for now. As always, we believe if you’re using a database, it should be version controlled. Whatever your sue case, drop us a line on Discord and we’ll help you figure out how Dolt can benefit you. If you like the idea but aren’t sure if Dolt has the right feature set for your project, come chat with us about it! We take user feedback seriously and use it to prioritize new features.
Footnotes#
-
The actual encoding of a chunk is a more complicated than this. Table chunks are flatbuffers, whose schema you can read here. But for the purposes of this, we’re going to pretend that chunks are stored as a simple two-dimensional array of values. ↩