
Dolt is the first version controlled relational database. Among other things, reliable databases have fast and reliable query plans. We can make most queries fast with combinations of macro structural rearrangements like filter pushing and column pruning. But that is not enough for the trickiest joins.
Table ordering and index selection are the two main drivers of join performance, and they depend on table data. We have increasingly relied on table statistics as the last defense for optimizing difficult joins. These bits of metadata let us efficiently simulate thousands of join orderings before choosing the most optimal.
We’ve been working on statistics based optimizations for over two years now. This diagram summarizes the progress we’ve made in that time.
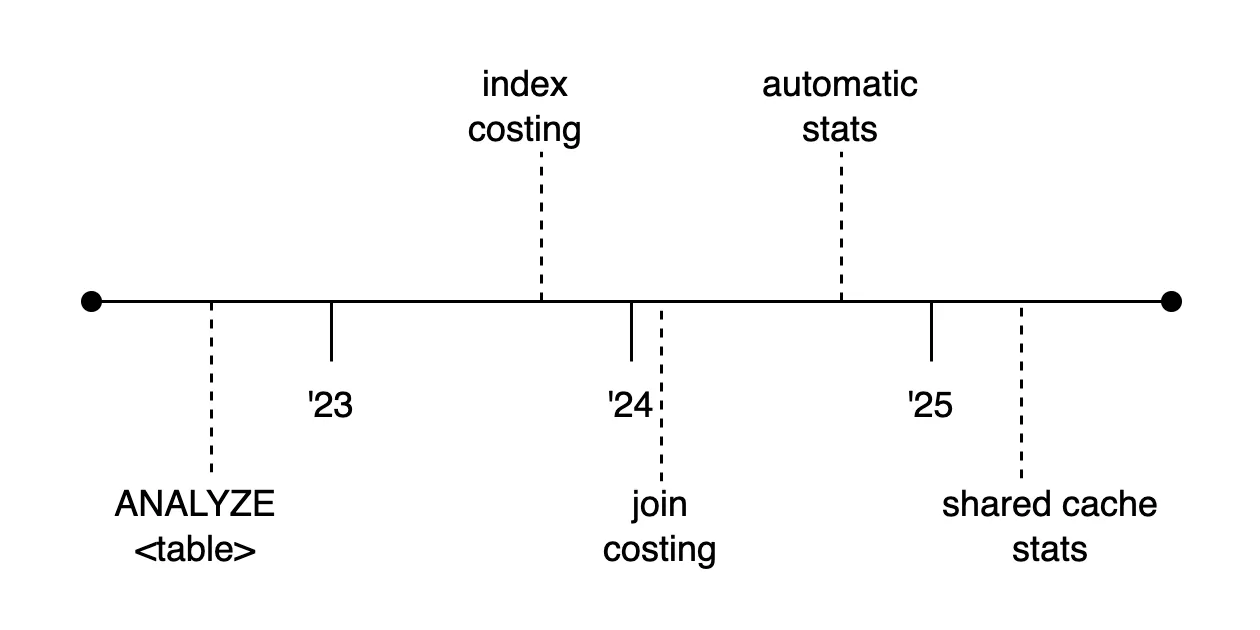
We added ANALYZE support with transient histogram buckets in 2022. In 2023 we added costed optimization phases to analysis, first on index scans and then on joins. And by the end of 2024 we’d ironed out enough bugs in collection, storage, and costing to turn statistics collection on by default.
Dolt version 1.51.0 includes a rewrite of table statistics. We
described in our last
post about how
we were motivated by performance and scaling concerns. Here we will talk
more generally about the user-facing aspects of statistics 2.0.
Managing Statistics#
Most users will not notice or need to worry about statistics collection. Running dolt sql-server by default launches a background thread that keeps statistics fresh. A helper function dumps the coordinator’s state if you are interested in peeking behind the curtain:
testdb/main> call dolt_stats_info();
+---------------------------------------------------------------------------------------------------------------------------------------------------------------+
| message |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------+
| {"dbCnt":2,"active":false,"storageBucketCnt":0,"cachedBucketCnt":219,"cachedBoundCnt":5,"cachedTemplateCnt":5,"statCnt":5,"genCnt":1,"backing":"testdb"} |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------+The main time users might want to interfere with statistics are during heavy import workflows. Statistics only contribute to optimizing read queries. So batch imports create a constant churn of catchup work for the statistics thread that produces no benefit for the write workload. In this case it makes sense to disable statistics, either before or after the server starts:
> SET @@PERSIST.dolt_stats_enable = 0; --disable stats on next restart
> call dolt_stats_stop() -- stop collection thread
> call dolt_stats_purge() -- stop thread and free main memory and storage caches
Statistics updates are rate-limited by default. The statistics thread partitions an update into jobs, and only a certain number of jobs will be processed within the @@GLOBAL.dolt_stats_job_interval milliseconds. A high job interval or large number of databases/branches/tables/indexes all increase the amount of time in-between statistic updates. Users who want snappier statistics at the expense of sharing CPU resources can lower the job interval.
Users who want manual control over updates can turn off statistics with call dolt_stats_stop() and then use call dolt_stats_once() to trigger individual collections, for example on a daily cron schedule.
testdb/main> call dolt_stats_once();
+---------------------------------------------------------------------+
| message |
+---------------------------------------------------------------------+
| {"dbCnt":2,"bucketWrites":51,"tablesProcessed":5,"tablesSkipped":0} |
+---------------------------------------------------------------------+Short Deep dive#
It has been awhile since we have detailed the inner workings of statistics, so I wanted to give a recap here.
There are two main statistics objects, a bucket and a histogram, or collection of buckets. Histograms track the shape of a specific level of the prolly tree. In the example below, we’ve marked the second level of the tree in green to indicate it’s the statistics metadata level.
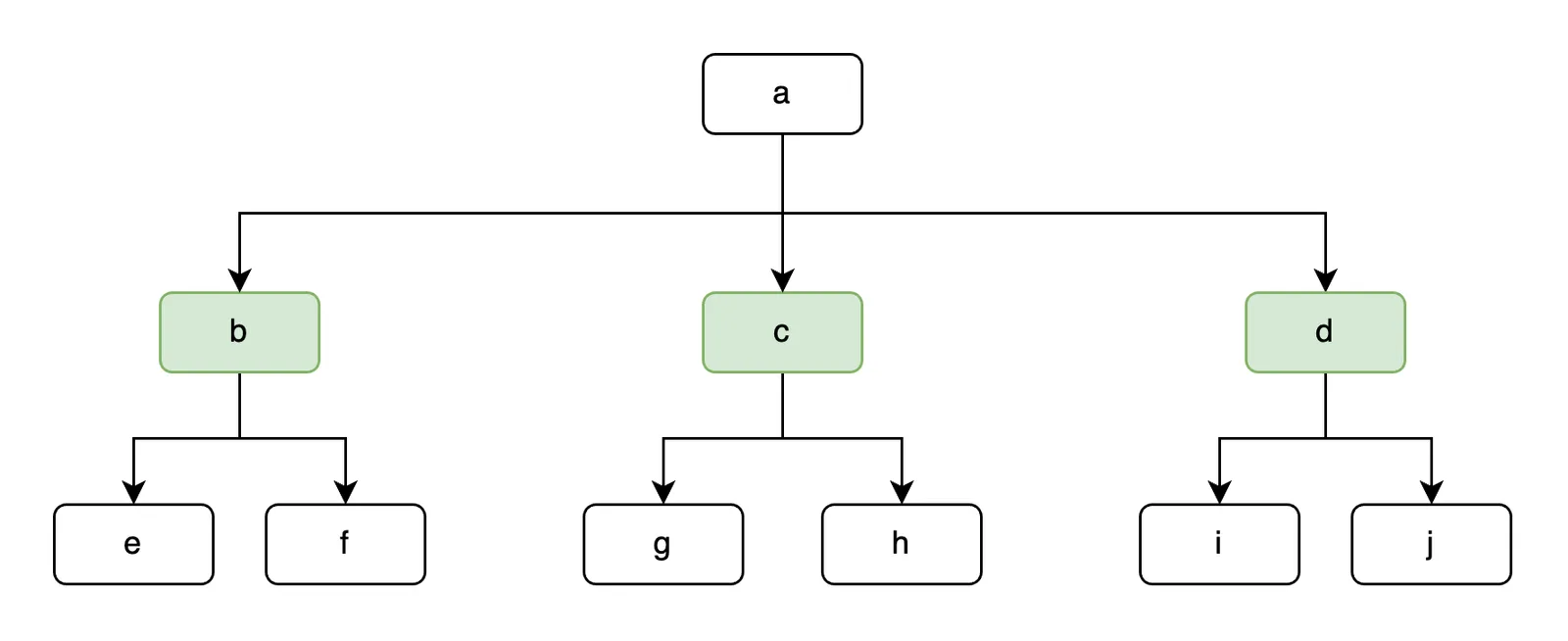
Our histogram for this index would then have three buckets: b, c, and d. These content addressed buckets summarize statistics from their fraction of the tree. Buckets track row and unique counts deterministically and exactly. Buckets are saved in a shared memory cache where branches share references, and eventually flushed to the disk cache so restarts avoid recomputing buckets.
The diagram below shows how the intermediate level chunks b, c and
d are processed into buckets saved into memory and storage caches.
Index histograms, like PRIMARY, reference the cached buckets by pointer.
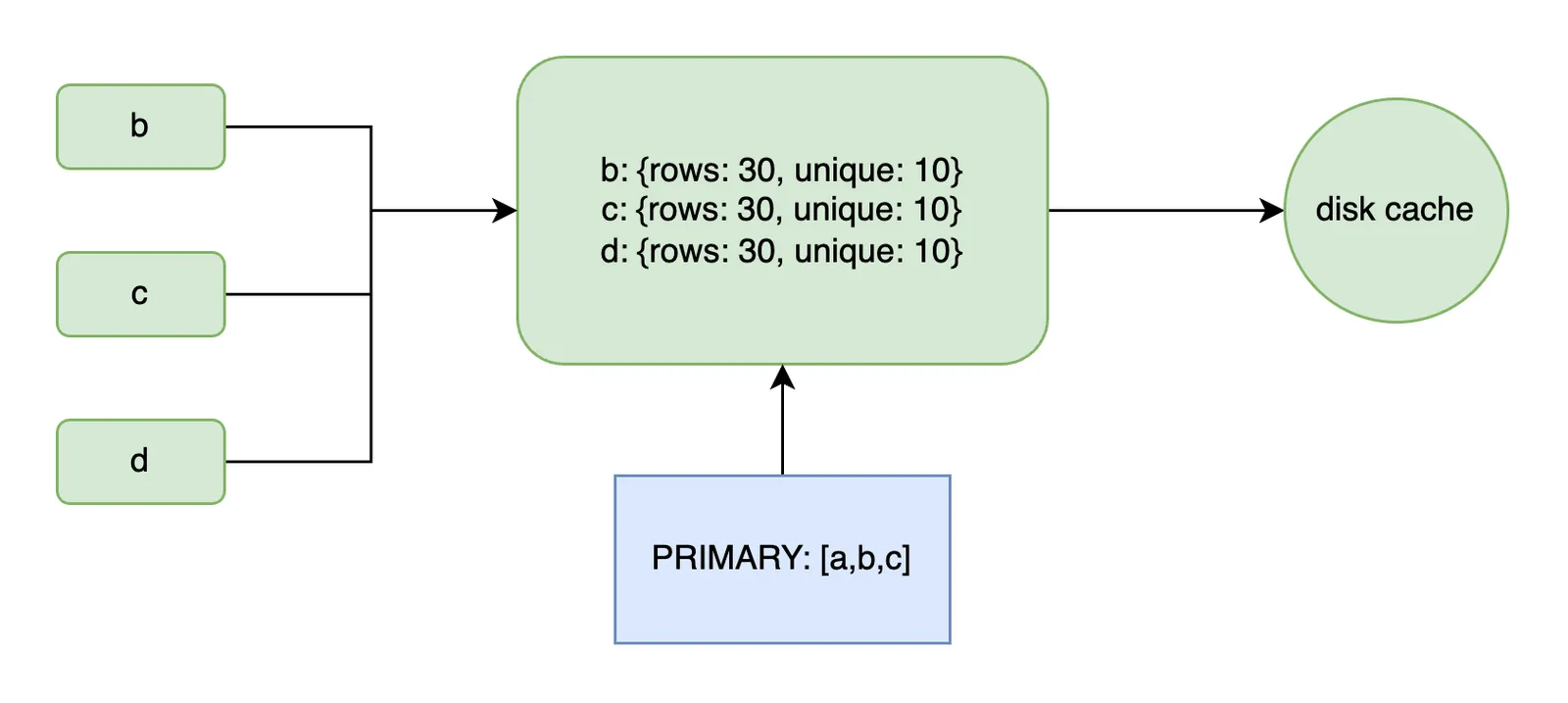
A “statistics collection” (or “cycle” or “update”) walks all of the databases in an immutable session root. Every index reserves a histogram represented as a list of pointers to cached buckets.
Because buckets are content addressed, a collection cycle often only recalculates a handful of buckets for updated indexes (batch imports being the exception). When the session root walk is finished, the new set of histograms are wholesale swapped with the old.
Over time, the chunk caches in memory/storage accumulate buckets that are no longer used. The garbage collection process is a sidecar to a collection cycle, creating new memory cache that replaces the old at the same moment histogram stats are swapped.
Upcoming Work#
We are pleased with the scalability and testability of the new statistics architecture. But there are still hotspots to improve.
The write-heavy use case can be tricky. For example, the first release had a gap in rate-limiting where large flushes to disk starve user queries. We can flush memtables eagerly to avoid the buildup. But even with rate limiting, write heavy workloads churn buckets out of date before they are even available on the read path. Users can opt out of statistics the same way they opt out of constraint checks for imports. But there are already a lot of things to remember, relational databases should reduce the mental load of storing data.
The new architecture also makes it possible to improve the stats read path. First, we can streamline stats access by removing function calls, interfaces, and copies that were necessary in the previous version. Additionally, we are interesting in expanding and optimizing the range of metadata we can use to improve query estimates.
Summary#
Dolt 1.51.0 includes the new version of table statistics. Servers
automatically start the background statistics thread, which performs
a fixed amount of work per unit time regardless of the database size or amount of work
per update.
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!