
This is an intervention (but mostly a rant).
Maybe it’s for you, or maybe it’s for me—perhaps it’s for both of us. Regardless, it’s time we face reality and stop pretending we’re already living in the year 3000.
We’re being conned by Big LLM, and I’m here to call them out.

What is this “con” you might be wondering? The “con”, as I call it, is that Big LLM is actively perpetuating the myth that running LLMs is practical and useful. This is a lie.
More specifically, my claim is that Big LLM is purposefully obfuscating the cost of running LLMs, because if the people actually knew the cost, they’d riot. Well, they wouldn’t riot. But they definitely stop believing all the hype surrounding AI and LLMs and especially open-source models.
In fact, I’m willing to go a step further and say you can’t actually run them.
Now sure, you can run a quantized or lower parameter model that’s supposedly jUsT aS gOod as the full model (not that the full model is very good to begin with) in your dumb-ass, AI recipe generator side project you vibe-coded last weekend. But you can’t run a full model, you simply can’t afford to, GPU compute is way too expensive.
And, if you’ve made this side project I’m talking about, like I have, is it really worth $5,000/month to generate the most basic-bitch lasagna recipe you’re not even gonna actually cook anyway? We both know the answer is “no.”
As the adage goes, show me someone who claims they’re running a low parameter model effectively and I’ll show you a liar.

Speaking of the differences between the full models and their supposedly more economical counterparts, have you noticed that the published performance benchmarks by Big LLM are always for the full parameter versions of models?
For example, look at this image by Google about its new Gemma 3 model performance:
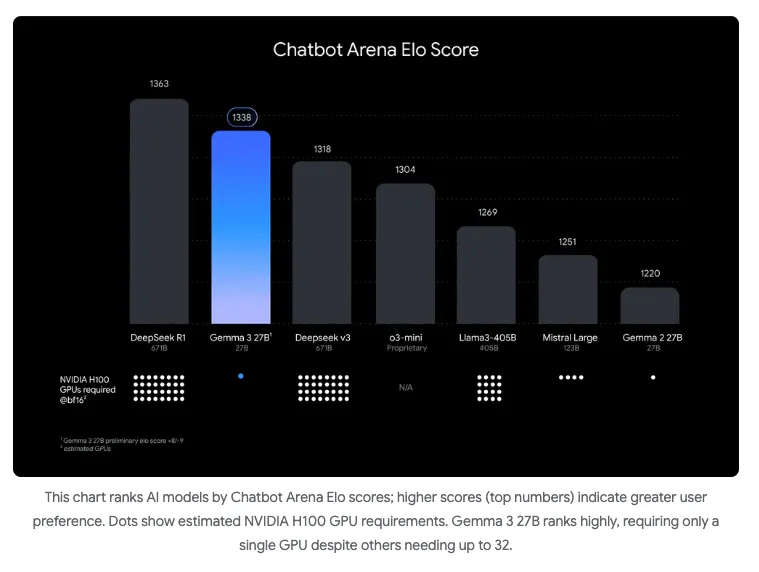
The tagline for this shiny new shit is “the most capable model you can run on a single GPU or TPU”. Like other LLMs, Gemma 3 comes in a variety of quantization and parameter sizes, but this image shows results for the full 27 billion parameter model as measured against other full models, like Deepseek-r1 with 671 billion parameters. At the bottom of the image it shows dots representing the number of GPUs it takes to run inference on the tested models.
According to the image, full Gemma 3 outperforms Deepseek-R3 671B and Llama3 405B with just a single H100 GPU, whereas the other models take 32 and 16 H100 GPUs to run inference respectively. In case your eyes glazed over there, let me repeat this fucking bullshit.
To run the full Deepseek model it takes 32 H100 GPUs, and to run the full Llama 3 model it takes 16! For fun, let’s say that you actually wanted your recipe app to be the best it could possibly be, so you plan to add a full version of these models to it. The cost of running these yourself on AWS would be about $292,000/month to run Deepseek and $145,000/month to run Llama 3 405B.
I calculated these numbers by looking at the on-demand prices for EC2 instance types that had H100 GPUs. This is the p5 series. Each p5 instance has 8 GPUs, and costs $98/hour to run. If you run 4 instances for Deepseek-R1 (to get to 32 GPUs), that’s 98 x 4 x 24(hours) x 31 (days in a month), which gives you about $292,000/month. The same process yields $145,000/month for Llama3 405B.
This is an obnoxious amount of money, and it’s exactly why I’m saying you can’t run this stuff, and Big LLM knows you can’t run this stuff, but keeps lying to you, suggesting that you can.
“But, Dustin,” you’re probably thinking, “the point of Gemma 3 is that you don’t NEED all that GPU power anymore. You can get comparable, even better results with only a single H100, that’s the whole point of Gemma 3!”
Well, guess, what, I have some more bad news for you.

Buying an H100 yourself would cost you about as much as a new car.

And the cheapest on-demand instance you can get with an H100 on AWS is $98/hour, which still has 8 GPUs. There’s no single H100 GPU instance on AWS. Instead, you can head over to Google Cloud and get an A3 instance type with a single H100 for only $9700/month, or $116,000/year.
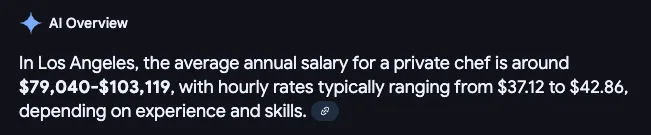
On the surface, maybe that seems like a much more tolerable number compared to what’s available on AWS… until you realize its cheaper throw your app in the garbage and just hire a private fucking chef!

But maybe it’s all worth it, right? Maybe running Gemma 3 is more useful than putting your hard-earned money in a garbage can and setting it alight. Maybe it will actually make you money somehow.
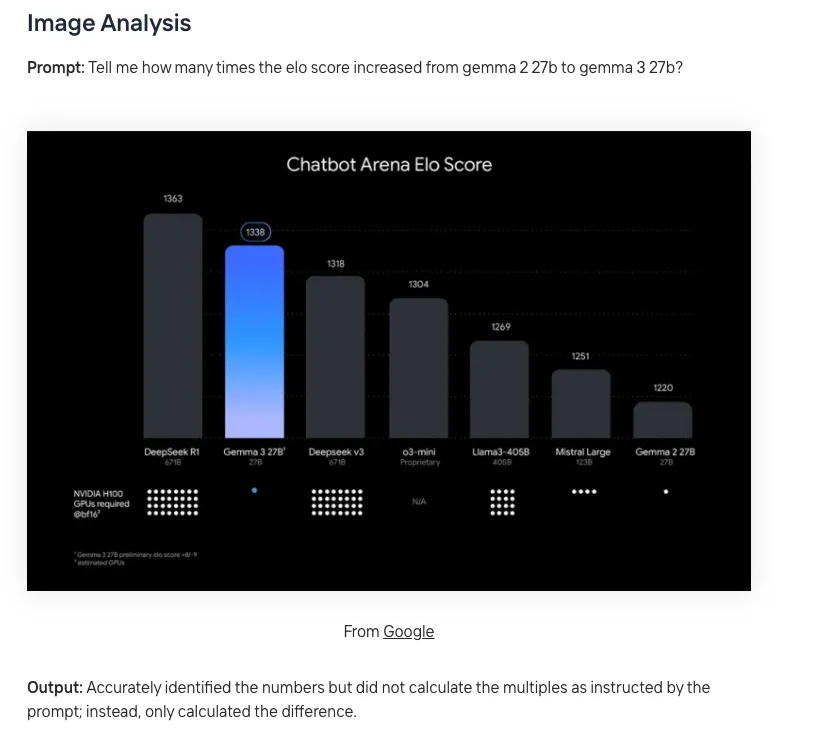
Well according to the guys at Novita who actually coughed up the money to run the full Gemma 3 27B model, it’s a whiz and calculating fruit, much like a $9700/month calculator app, but it still sucks at coding and following directions:


Are you starting to see what I’m saying? Does this all not smell funny to you? To me, Big LLM is starting to reek of snake-oil.
Literally right now, as I’m typing these words, I’m ignoring all the auto-complete suggestions my “smart” IDE is suggesting cause it’s so bad at writing good content. I mean, I’m also bad at writing good content, but that’s a topic for a different blog.
As I sit here, I can almost hear the remote H100s powering my IDE humming violently in the distance while, in my brain, tell my IDE: NO, I DON’T WANT TO TYPE THAT, YOU SUCK, FUCK OFF!!
And I hate to just pick on Google and Gemma 3, cause it’s not just them, it’s like, ALL of Big LLM.

One more example. Take this recent video posted by IBM that entered my youtube feed.
When I was growing up, IBM used to be a legit tech-company. I’m not sure if they still are, but they recently put out this video that is a perfect example of how Big LLM is conning us.
The video is supposedly instructing you on how to run an open source LLM on your own hardware, without “running your own server farm of GPUs that dim the lights every time you ask it to do something”, as the host of the video “jokes” (although I would argue he’s not joking).
Later in the video, Robert Murray, the guy on the right, says he pulls down the Llama model from Ollama, and later on he reveals that this is either the 7B parameter or 14B parameter model he’s recommending you run on your own hardware. Immediately when he says this, I wanted to turn the video off. I mean what’s the point of running these things, we all know they suck, they can’t even crack the benchmarking images!
Soldering on, at about the 4:10 mark, Robert is asked about the minimum hardware requirements for running these models. He says 8GB of RAM is the minimum, although he personally runs 96GB. LOL, Robert, what?! Where the fuck did he get only 8GB from, when he’s running 96GB?
Robert then remarks that he has run “up to 70”, locally, meaning he’s run the 70B parameter Llama model but that it was “slow”. It’s literally the only word he uses to describe the experience of running a model of that size. Mind you this is still nowhere near the full 405B parameter LLama 3 model that Gemma 3 supposedly dunks on.
Hilariously, when Robert is asked about the recommended GPU for running these models, knowing full well that we are watching this video to avoid running “a server farm of GPUs”, with a HUGE grin, Robert simply says, “the more GPU, the better”, and draws a little fucking plus sign next to the word GPU on screen.
THAT’S IT! That’s all that’s mentioned about the GPU required for running models yourself.
This is what I’m talking about! Big LLM keeps putting out content like this trying to convince us that this shit is real but it’s not. They’re trying to get us to spend money on GPU hours for no reason, and they’re laughing about it right in front of our faces.
So since Robert at IBM didn’t tell me how many GPU’s I’d actually need to run LLama 3 14B, I went over to the “smartest” LLM I currently have access to, Chat GPT’s o1 model. Here’s what it said:


Hmmm, it seems like I would still need a fuck-load of GPU after all, Robert! Why didn’t he just tell me this? Is he part of Big LLM? Is Robert also a confidence man?
Or, maybe the o1 model is… wrong? If the o1 model is wrong, does that mean all 1400 H100s powering it are also just a huge waste of money and compute?
I guess we will all find out soon enough, but I hope I’ve successfully sown the seeds of doubt about this whole industry in your mind. I mean, it’s not like other people out there are starting to realize that Big LLM is just lying to all of us, right? Oh, wait…
In the meantime, let me do you all a solid, and save you $10,000/month:
If you have pasta and tomato sauce in your pantry, just make fucking spaghetti for dinner.
Conclusion#
I hope you found this rant fun to read. I probably only believe about 85% my claim, but sometimes you have to commit to the bit to sell it!
We’re still trying to find ways to make AI useful and affordable over here at DoltHub. As always, we’d love to hear from you. If you have any suggestions or feedback, or just want to share your own experiences, please come by our Discord and give us a shout.
Don’t forget to check out each of our cool products below:
- Dolt—it’s Git for data.
- Doltgres—it’s Dolt + PostgreSQL.
- DoltHub—it’s GitHub for data.
- DoltLab—it’s GitLab for data.
- Hosted Dolt—it’s RDS for Dolt databases.
- Dolt Workbench—it’s a SQL workbench for Dolt databases.