
I ran into a performance trade-off last week attempting to improve long-running queries by changing the ways rows are structured. A more general row interface increases memory overhead but lets us skip encoding overhead. Unfortunately, joins create so many rows that even that small a overhead was unacceptable. We are finding increasingly that a change that makes one query fast makes another slow.
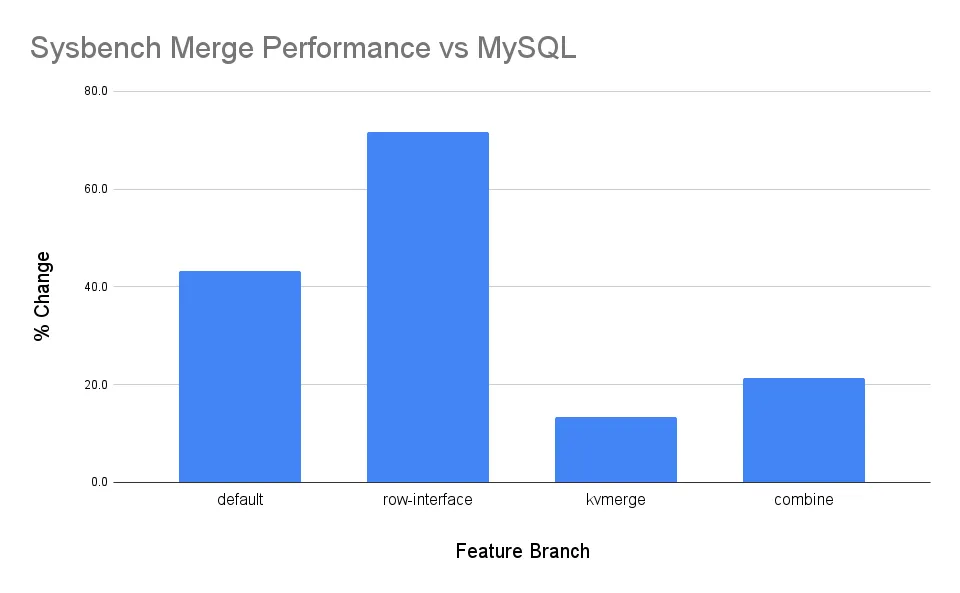
The plots above are for our merge join sysbench test, index_join_scan, run on four different Dolt branches. “Default” is Dolt 1.43.17, “interface” is a PR branch abstracting SQLRow, “kvexec” rewrites merge join in our KV layer, and “combined” is the net effect of the interface and kvexec changes.
| test | sysbench | perf Δ |
|---|---|---|
| mysql | 1.27ms | - |
| default | 1.82ms | +43.3% |
| interface | 2.18ms | +71.7% |
| kvexec | 1.44ms | +13.3% |
| combined | 1.54ms | +21.3% |
As you can see from the “kvexec” and “combined” numbers, we managed to convert a regression into a win. We started at 43.3% worse than MySQL. The first approach, default shown above, was 71.7% slower than MySQL. Finally, we ended up at only 13.3% worse for the kvexec approach and 21.3% worse for the combined approach.
We will detail the original change, what went wrong, how how rewriting merge join to execute in our key-value layer compensated.
Interface Change#
Rather than a row being a list of Go types:
type Row []interface{}I want to disguise byte arrays behind an interface:
type Row interface {
GetValue(int) interface{}
SetValue(int, interface{})
Copy() Row
}With the default case still being a slice:
type DefaultRow []interface{}I expected little performance difference, but I was surprised by how worse the second version is for merge joins:
| test | ns/op | bytes/op | allocs/op |
|---|---|---|---|
| default | 402k | 167k | 5.9k |
| interface | 612k | 312k | 12k |
| kvexec | 281k | 110k | 3.4k |
| combined | 320k | 137k | 4.5k |
Above runs the same sysbench query on the feature branches in the intro with Go’s benchmarking package. This isolates the CPU work from the tooling, server, and network overhead. Notably, the allocation space and frequency doubles between the “default” and “interface” runs. “kvexec” and “combined” both temper memory usage.
Interface Slices#
Above we saw that storing result rows in an interface expands a merge join’s allocations by 2x, from 6k to 12k. Why is this the case?
Consider copying an interface slice:
type DefaultRow []interface{}
func (r DefaultRow) Copy() Row {
cp := make([]interface{}, len(r))
copy(cp, r)
return DefaultRow(cp)
}
var result Row
func BenchmarkCopyDefaultRow(b *testing.B) {
var res DefaultRow
var r DefaultRow = make([]interface{}, 1)
for i := 0; i < b.N; i++ {
res = r.Copy().(DefaultRow)
}
result_ = Row(res)
}The loop copies a DefaultRow into a DefaultRow type result variable. After the initial setup, each loop copy allocates once and consumes 16 bytes:
BenchmarkCopyDefaultRow-12 47347862 22.04 ns/op 16 B/op 1 allocs/opInterface objects have two components: an 8 byte interface type, and an 8 byte pointer to the underlying struct. This all checks out so far: make([]interface{}, 1) is one allocation and each array slot has a type and data pointer.
Below includes a small change that simulates our interface PR. We replace
the static var res DefaultRow with the interface var res Row. From
a strategic perspective, this lets us perform byte array tricks through
shared methods without always materializing fields as Go types:
func BenchmarkCopyRow(b *testing.B) {
var res Row
var r DefaultRow = make([]interface{}, 1)
for i := 0; i < b.N; i++ {
res = r.Copy()
}
result_ = res
}From a practical standpoint, the substitution results are slow:
BenchmarkCopyRow-12 24976800 46.90 ns/op 40 B/op 2 allocs/opAn interface slice that escapes to the heap adds an extra layer of abstraction. An 8 byte reference to the underlying array, an 8 byte size, and an 8 byte capacity. So on top of the original 16 bytes and 1 allocation, we now have +1 allocation for a heap slice that takes 3 * 8 = 24 bytes.
With this in mind, 2x difference in sysbench allocations makes more sense. Each new row performs two allocations now instead of one. And if the average row size for our merge join is ~two items, we’d expect the byte use to climb by about 56/24 = 1.75x.
We might look into ways of amortizing or recycling the extra heap objects at some point, but in the meantime there is a more direct way.
KV Merge Join#
Implementing logic at the KV layer bypasses conversions between the KV and SQL presentation layers. Solving this for lookup joins was a priority because that execution operator crosses the boundary several times. But if we want to build more aggressive SQL row optimizations, all row hungry operations are better implemented in KV logic.
The most interesting implementation detail of KV merge join is how non-covering secondary lookups have a straddled life cycle.
As a quick reminder, a merge join walks two sorted indexes whose prefixes correspond to a join filter. For a join that returns a lot of rows, sequentially reading both indexes is faster than random index reads.
A non-covering index typically first reads a small index comprised of (1) the index columns and (2) the primary key. A follow-up lookup into the primary index backfills the rest of the columns needed to complete the logical row. Typically we combine these two index accesses.
But the benefits of a sequential read obviously dissolve if every sequential read is paired with a random read.
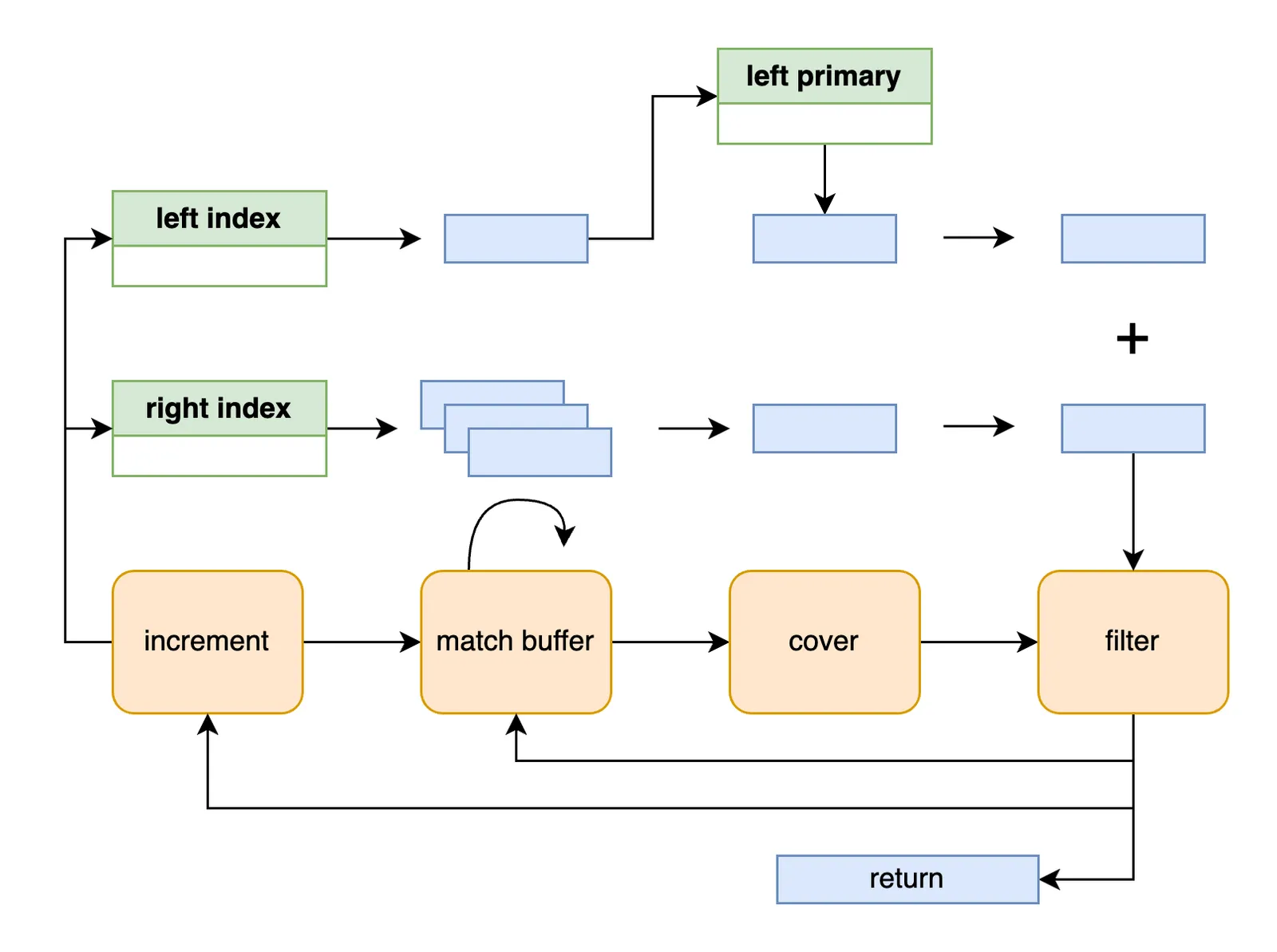
The diagram above describes the merge flow. When the left and right table keys do not match, we increment the smaller. After finding a match we accumulate a right-side buffer if a set of left and right rows need to cartesian match. For each potential match, we cover non-converting indexes with a primary lookup and then check the rest of the join and filter conditions. We return successful matches, loop through the match buffer until it is empty, and fallback to iteration when we need to advance the indexes to seek more potential matches.
A KV merge join carries the same performance gains and risks/present
limitations as the KV lookup
join we introduced a
couple months ago. Code coverage decreases when we reimplement SQL
logic. Narrowly defined interfaces have a smaller surface area than
customized execution pathways. We do not currently perform operator
fusion between kvexec nodes, only leaf joins benefit from the speedup.
And there are certain scalar expressions that we would need to implement
on byte arrays for KV join support.
But all of these gaps are fixable, and the result for common joins is quite performant. We are only about ~20% slower than MySQL executing in-memory merge joins now!
Summary#
We aim to minimize the amount of unnecessary work our SQL engine performs, but we’re starting to run out of optimizations that benefit all queries equally. More often we can make one shape of queries faster at the expense of a different kind.
Today we talked about an in progress change that in isolation crushes merge join performance. We would still like to make the original changes, and so we added a second complementary optimization that at the end of the day makes everything faster.
We are keen on continuing to make the engine faster! We are happy with two steps forward and one step back.
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!