
DoltDB is the first relational database that supports Git-like version control primitives like branch, diff, and merge. All our versioning features exist alongside full MySQL compatibility and near MySQL latency parity.
The latest release includes our next improvement of join planning machinery: automatic background statistics. We spent 2024 dog-fooding and improving statistics and are now releasing it into the wild.
Default automatic statistics currently meet a few of our main goals:
-
Better read performance for all queries compared to no-statistic costing. Join and index analysis is faster, execution plans are better, and there are paths to make analysis faster, estimates more accurate, and provide even better execution plans.
-
Collection does not impact query latency. The overhead of stats collection is a concern, but background statistics collection at the moment does not affect the latency or throughput of servers that are not connection saturated. (We talk more later about improving resource management and stability.)
-
Error states do not affect normal server operations and fallback to non-costing defaults. We cannot claim to have fixed every bug, but we have fixed enough bugs to smooth the user experience when something does go wrong. Later we talk about improve features for resetting corrupted statistics and how error handling has improved.
We hope you enjoy this new feature! The docs, and statistics can still be stopped, dropped, and disabled at any time:
call dol_stats_stop(); -- stop automatic collection
call dolt_stats_purge(); -- drop statistics db
set @@PERSIST.dolt_stats_auto_refresh_enabled = 0; -- disable stats threads on sql-server startHistory of GMS Joins#
We inherited go-mysql-server with only inner join support. Below is an abbreviated history of how join planning has evolved over the last 5 years:
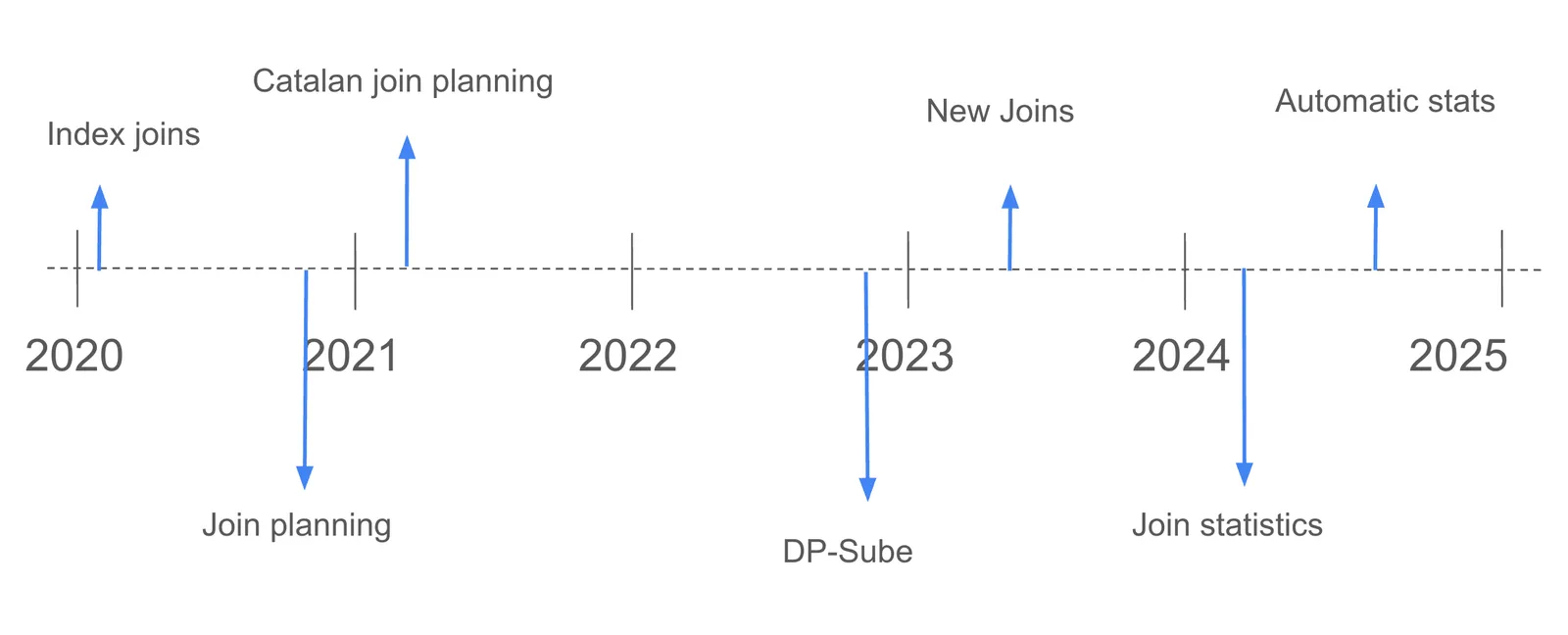
-
Added indexed joins: The first non-inner join operator that performs much less work for big tables compared to an inner join.
-
First join planning: Prefer join orders that index join small tables low in the tree.
-
Catalan join planning: Efficient planning that scales to larger tables.
-
DP-Sube join planning: More efficient planning that saves partial plans and is amenable to cost-based decision making.
-
Expand the number of join operators available (merge, hash, lateral)
-
First costed joins with offline statistics
-
Costed joins by default with automatic statistics collection
This latest update adds the last component that DoltDB was missing compared to Postgres and MySQL. Our optimizer and join planning is still very patchwork. But it is a featureful, correct, and fast patchwork that is getting better every month.
Stability Improvements#
The media_wiki import helped improve statistics collection stability.
It was a big database with a complicated schema,
and functioning statistics greatly improved import speed.
No Stop The World#
Updating statistics while continuing to import was necessary. The previous stop-the-world hacks that we used to get statistics up and running were replaced with critical-section only locking.
Stable Non-Numeric Statistics#
media_wikis indexes included non-numeric types that we did not focus
on during our initial testing. We worked through quite a few rare string formatting issues that the
volume of data helped expose. We now
use the core database serialization for bound rows and most common
values.
Better Logging#
The database was so hard to clone that better error handling and logging were also necessary to understand what was going on at a distance. All errors are now debug logged for transparency.
Easier Deleting#
There were so many bugs that we needed to add dolt_stats_purge() to
make it easier to wipe the stats cache:
call dolt_stats_purge(); -- deletes/recreates the stats cache folder (.dolt/stats)Garbage Collection#
And the import created so much turnover that we needed dolt_stats_prune() to
garbage collect/discard old data:
call dolt_stats_prune(); -- delete/recreate the stats cache without losing in-memory statsForward Looking#
All databases worry about the overhead of stats collection impacting regular query operations. DoltDB has a few advantages and a few disadvantages here.
Our updates use diffs to avoid updating statistics for portions of the database that have not changed. This means we can tune updates to depend on the fraction of table data that has changed. We also often only process the fraction of data that did change when performing an update.
Writing histogram buckets to Prolly-Trees does have some downsides for IO efficiency and stale log retention. Writing data to LSMs lazily would improve write efficiency and disk amplification, and make it easier to garbage collect old statistics.
Because Dolt is written in Go, the built-in scheduler owns resource management and controls how much CPU time is spent executing background threads. At some point we may write our own resource managers to have more control.
Coupling the shape of Prolly Trees to histogram buckets limits statistic use. We lack control over the exact bucket count, which is often higher than the average database. There are ways we could consolidate histogram buckets in the background to reduce the amount of computations joins perform during analysis. The deterministic shape and contents of histogram buckets also cannot benefit from partial sampling, which speeds the process in other databases. Finally, index-based statistics cannot estimate the cardinality of nested joins the same way column-based statistical approaches can.
We currently meet our main goals with the set of chosen trade-offs. But there is always room to improve! And certain use cases might force us to provide different sets of tradeoffs.
Summary#
We turned automatic statistics collection on for all databases. The next
time you restart your sql-server with a Dolt version >= 1.43.8, a
background thread will poll and update table tracking histograms.
Histogram statistics are used for choosing index and join orders and
indexes. If all goes well, many queries will silently get faster.
If all does not go well, send us an issue in our Git
repo and we will usually fix it the same day.
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!