
MySQL’s replication protocol is widely used to help systems achieve high availability, load balancing, and data redundancy. The replication protocol was originally introduced waaaay back in 2000, and in the more than two decades since then, the protocol has evolved and become extremely popular. In this blog post, we’re taking a deep dive into some of the details of the MySQL replication protocol, paying particular attention to some of the messages sent between a replica and the primary server.
We’ve been digging deep into MySQL’s replication protocol for a while now, as part of adding support for MySQL replication to Dolt DB – the world’s first, and only, SQL database with Git-style versioning. We support replication from a MySQL database to a Dolt database and we’re actively working on building Dolt to MySQL replication. We’ve learned a lot about the MySQL replication protocol along the way and we’re happy to share some of what we’ve learned!
What is MySQL Binlog Replication?#
Database replication allows multiple database instances to stay in sync with a primary database instance. This is useful for a wide variety of use cases, with the most common being high availability, load balancing, and data redundancy. In a high availability scenario, if something happens to the primary database instance, a hot standby must be ready to be immediately swapped into service. In a load balancing scenario, read queries can be distributed across multiple replicas. This helps to reduce load on the primary database, which must handle all write requests. In a data redundancy scenario, data is replicated to multiple locations to ensure that data is not lost in the event of a disaster.
With MySQL replication, a source server logs events to an append-only log, known as the binary log. When a transaction is completed, the source server writes an entry to the binary log that records how the data changed. When a replica connects to the source server, the source reads from the binary log and streams those same events back to the replica, while the replica applies the changes on its side.
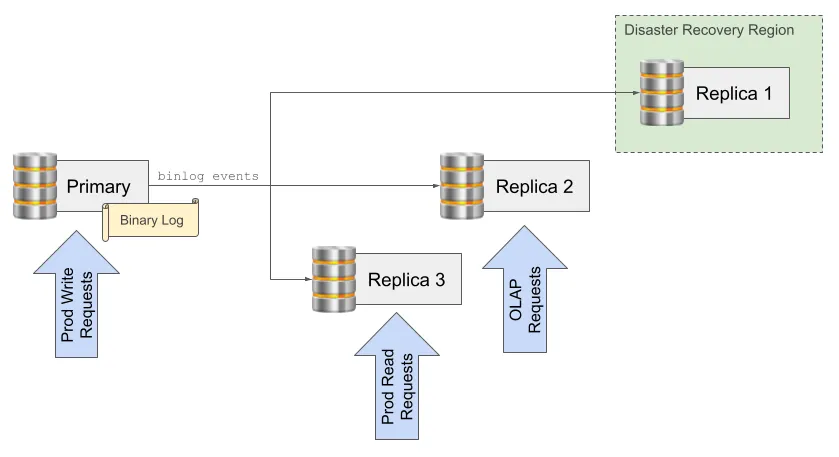
In the diagram above, the primary server is sending binlog events to three replicas. All write requests from the production application go to the primary database, and read requests from the production application are routed to replica 3 in order to spread the database load from the production application. Replica 2 handles longer running analytic queries that could otherwise slow down production queries, and replica 3 is in a different region to provide data redundancy.
MySQL Binlog Replication Protocol#
At a high level, replication is very simple – the server records events, sends them to the connected replicas when they’re ready for them, and each replica replays them. However, as we get into the details, there is quite a bit of complexity. In this section, we’ll dive into that complexity to look at how the primary and replica coordinate, how replicated data is encoded, and common sequences of binlog events.
Replication Options#
The MySQL replication protocol has been around a loooong time, and over the years, the protocol and available configuration options have evolved quite a bit. Two major changes to how MySQL replication works were the introduction of GTID-based automatic positioning, and the row-based replication format. In the sections below, we’ll briefly explain each.
Positioning#
A replica and primary server need a way to coordinate on the position in the stream of replication events. This enables a replica to reconnect to a primary and continue the replication stream from the last event it was able to process. In the earliest versions of MySQL’s replication support, the only way to do this was to specify the binlog file name and the byte position in the file. In 2012, with the release of MySQL 5.6.5, a more robust way to do this was introduced with Global Transaction Identifiers (GTIDs). GTIDs are unique identifiers for each transaction that is generated by the primary server. A GTID is composed of the server’s UUID (@@server_uuid) combined with a unique sequence number, for example 85716002-48f5-11ee-bff9-e71bd3cf9371:6. When a replica connects to a primary server, it tells the primary server the set of GTIDs that it has processed, and the primary server sends all transactions that have occurred since that position. This makes it much easier to reconnect a replica to a primary server and continue the replication stream and is the recommended way of positioning a replica in the replication stream. For the rest of this post, we’ll be focusing solely on GTID-based auto positioning.
To use GTID-based positioning, the primary and replica must have GTID_MODE enabled (see the GTID_MODE system variable for more details). When the replica configures the connection to the primary server, it must also specify SOURCE_AUTO_POSITION=1 to enable automatic positioning with GTIDs.
Format#
MySQL replication supports three different formats for encoding replication events: row-based, statement-based, and mixed. The format determines how data changes on the primary are represented in events sent to replicas.
The statement-based replication format has been around the longest and records the exact SQL statement that was executed on the primary so that it can be replayed on the replica. This means the replica will execute the exact same SQL statement that was executed on the primary. This is a simple approach, but it means the replica has to reparse the statement and also introduces problems with non-deterministic statements. For example, if the primary executes INSERT INTO t VALUES (1, 2, RAND()); the replica will execute the same SQL statement, but will generate different data. There are several other cases where statement-based replication cannot replicate data correctly, for example, the functions UUID(), SYSDATE(), LOAD_FILE() and USER(), or DELETE and UPDATE statements that use a LIMIT without an ORDER BY clause.
The row-based format sends the actual row data that changed in the transaction. This format was introduced in 2006, as part of the MySQL 5.1.5 release, and has been the default replication format for quite a while. In the example above with INSERT INTO t VALUES (1, 2, RAND()); the actual values inserted on the primary would be sent to the replica, not the SQL statement itself, so row-based replication is able to replicate the data correctly. However, there are cases where row-based replication is less efficient than statement based replication. Consider the case where a single, short update statement updates millions of rows in a table. With statement-based replication, this is replicated as a short SQL statement, but with row-based replication, it sends millions of rows of data to the replica. It’s also worth noting that DDL statements are always replicated as statements, regardless of the replication format. For the rest of this post, we’ll be working with row-based replication, including showing details of the Rows events that are sent to represent data changes in table rows.
The mixed format is a combination of the other two formats, where the primary server attempts to choose the most space efficient format for each transaction.
The replication format can be inspected and set through the binlog_format system variable, although it is preferred to use the --binlog-format command line option when starting the MySQL server, since this setting needs to be in place when the server starts. It’s also worth nothing that the binlog_format system variable has been marked as deprecated, indicating that it will eventually be removed. This also means that support for other non-row-based replication formats is subject to be removed in the future as well.
Starting a Replication Stream#
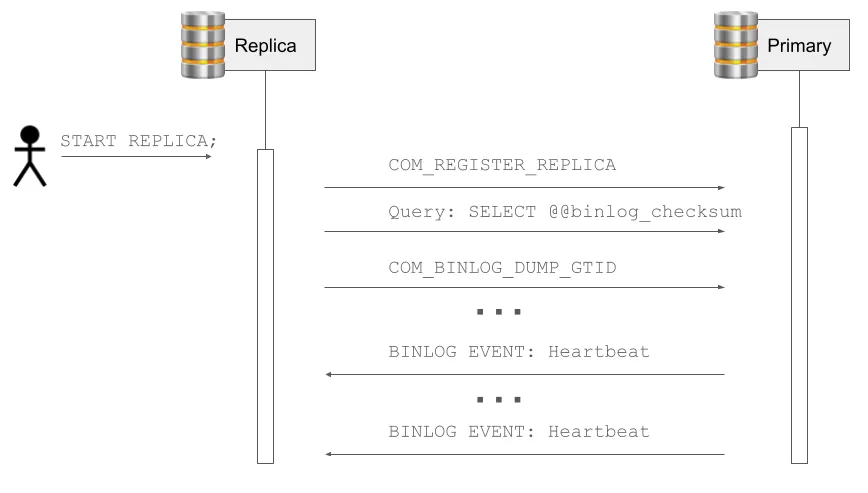
Once a replica has configured a replication source and is ready to start replication, it opens a connection to the source server and sends the COM_REGISTER_REPLICA command to register itself. It will also query configuration on the source server, such as grabbing the value of @@binlog_checksum. This is needed, because the replica needs to know if checksum bits are included in binlog events so it can correctly parse events before it receives a Format Description event from the source server. Once the replica is ready to start the stream of events, it will send a COM_BINLOG_DUMP_GTID command to the server, and the existing connection will be left open for the source to stream events back to the replica. To prevent the connection from timing out, the source server will periodically send a Heartbeat event to the replica. These Heartbeat events are synthetic events – they are never actually written to the binlog file, but are generated by the server to keep the connection alive.
Binlog Events#
Let’s take a closer look at some binlog events and see how they’re formed. In the first example, we’ll look at the initial events that a server sends back to a connected replica to begin the stream. Next, we’ll look at a DDL example where a new table is created. To wrap up, we’ll look at a DML example where new rows are inserted into a table.
Before we look at the individual events, let’s take a quick look at the structure of a binlog event, including the common header and checksum that wrap each event payload.
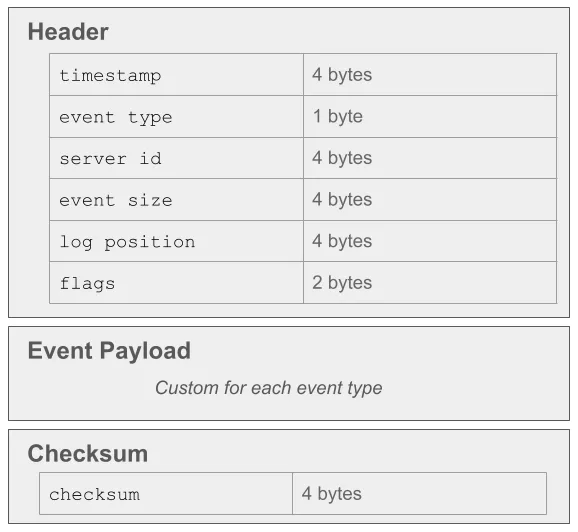
The same header structure is used for all binlog events. The event type field maps to the Log_event_type enum in the MySQL source code, and indicates which event is included in the payload. The replica uses this to determine how to parse the payload. The server id field is the @@server_id of the database that created this event. MySQL replication relies on each server in the topology having a unique server ID. event size is the total size of the event, including the header, the payload, and the optional checksum. log position indicates the byte position in the log file where the next binlog event starts. This field is particularly important for MySQL to verify integrity of the binlog event stream – if the log position doesn’t line up with what the replica is expecting, then the replica won’t apply the event.
After the common header, each event defines its own payload, and then if checksums are enabled, a 4 byte checksum is added after the payload. For the rest of the events we look at below, we’ll just be looking at their custom payload, but the event structure is the same.
Initial Events#
When a replica connects to a MySQL primary and requests a binlog stream, the primary always starts the stream by sending the Rotate, Format Description, and Previous GTIDs events (assuming GTID positioning is being used). These events have context about the stream that the replica needs to know in order to process the rest of the events. For example, the Format Description event describes if checksums are present on events, and the Rotate event tells the replica which binlog file is being read from.
Let’s take a look at the rotate event first…

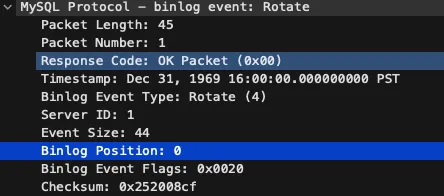
When a replica connects, a MySQL server sends the Rotate event to let the replica know what position the stream is at, which includes the byte position of the file, and the name of the binlog file. If this is the start of a brand new binlog file, then position will be 0x0400000000000000 (or ‘0x04’ in little endian encoding). It’s not 0, like you might expect, because every binlog file starts with the magic bytes 0xfe 0x62 0x69 0x6e to indicate that it’s a binlog file. For bonus points, interested readers can lookup what those bytes spell out in ASCII. 😉
This first rotate event is unique in that it isn’t actually written to the binlog file – a synthetic Rotate event is generated by the server to help the replica orient its position, but it doesn’t actually appear in the binlog file. In the wire capture below of a Rotate event, you can see that the Binlog position field of the header shows as 0, which means the next binlog event can be found as position 0 in the binlog file. In other cases, such as when a binlog file reaches its max size, a Rotate event is written to the binlog file, but this initial Rotate event when a replica first connects is slightly different.
After the Rotate event, the MySQL server sends a Format Description event:

The format description event tells the replica how to interpret the rest of the events in the binlog stream. The most important parts of the format description are the details on the checksum algorithm and the post-header lengths. The post-header lengths field is an array of bytes with one entry for each binlog event type, that indicates how long the header is for each event type.
The last event that the primary sends to the replica when starting a new binlog stream is the Previous GTIDs event:

The Previous GTIDs event tells the replica which GTIDs have been executed on the server before the current position in the binlog file. This tells the replica which transactions have already been processed and which ones need to be applied. A GTID uniquely identifies a single transaction, and a GTID set identifies a set of transactions (e.g. 85716002-48f5-11ee-bff9-e71bd3cf9371:1-6). Since a GTID set can contain GTIDs from multiple servers (i.e. multiple SIDs), the first field, num SIDs, indicates how many servers are represented in the GTID set. For each represented server, the sid field shows its UUID, and the num intervals field indicates how many sequence intervals are represented. For each of those represented sequence intervals, the fields start and end are repeated to indicate the inclusive start and inclusive end of the interval.
DDL Events#
DDL events, such as CREATE TABLE, have a relatively simple encoding for binlog events. DDL statements are always sent as Query events, even when row-based replication is in use. This means, the primary sends the replica the exact SQL statement executed on the primary, and the replica replays it.
To indicate the transaction boundary, the primary starts by sending a GTID event:

A GTID uniquely identifies a transaction on a server by using the server’s UUID to identify the server that created the transaction, and a sequence number to identify the transaction itself.
After the GTID event, MySQL sends a Query event that contains the DDL statement for the replica to execute, as well as additional metadata on how to execute it, such as the database in which to execute the statement.

The statement field contains the DDL statement that the replica will execute, and database indicates the database that should be active as the default database when running the statement. The status vars field contains a set of variables that indicate how the statement should be executed, for example, they can specify the SQL_MODE to use when executing the statement, or the character set.
DML Events#
Representing DML events in the binlog format is slightly more complex than representing DDL queries. These will typically start with a GTID event to mark the transaction boundary and then a Query event that runs the statement BEGIN to start an explicitly managed transaction. After that, we see three new types of events: the Table Map event, the Rows event, and the XID event.
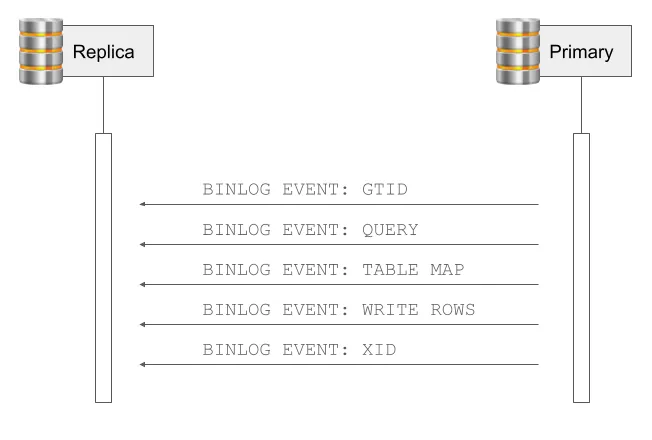
A Table Map event describes the structure of a table and assigns it a unique ID that is used in subsequent Rows events to refer to that table. The Table Map event is sent once for each table that is modified in a transaction.
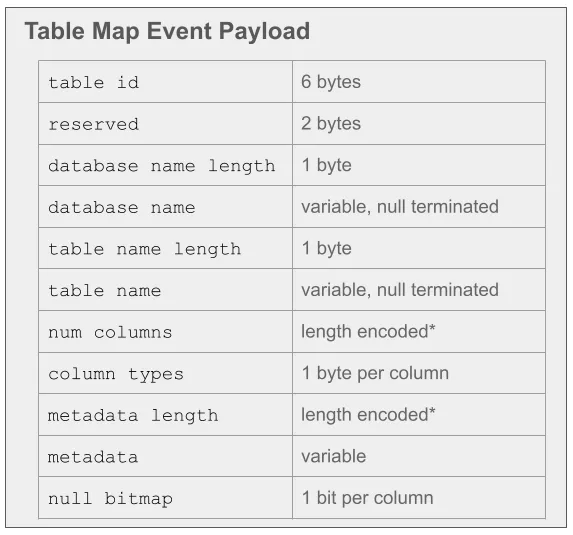
The Table Map event contains a lot of data about a table. The table’s schema is defined by the column types field, combined with the metadata field. For example, column type might indicate that the first column is a VARCHAR column, and then based on what type of column it is, the replica knows how to interpret the corresponding bytes in the metadata field for that column. In the case of VARCHAR, the metadata field contains the length of the string, encoded as a single byte if the length is less than 255 bytes, and encoded as two bytes if the length is 255 bytes or more. Other types use different metadata encodings; for example, for DATETIME columns, the corresponding metadata byte indicates the number of fractional seconds defined in the column’s type. The null bitmap field is a bitmap with one bit for each column; if the bit is set, then the column allows NULL values, otherwise it does not. Additionally, the Table Map event may also contain an optional metadata field that provides even more metadata about the table, such as all column names, the default character set and collation for the table, string values for enums, and much more.
After the Table Map event, the primary will send Rows events that describe how rows in each table have changed. These can appear as Write Rows events (for inserts), Delete Rows events (for deletes), or Update Rows events (for updates). Each type of Rows event has mostly the same structure, although Update Rows events contains some extra fields to enable the replica to identify the rows that are changing, as well as the new row values.

Each Rows event describes the existing data being updated or deleted, as well as the new data being inserted or updated. The cols used bitmap field indicates which of the columns defined in the associated Table Map event are included. For example, if a row is being deleted, the primary key columns can be specified, without having to specify all the other columns in the row. The null bitmap field indicates which fields are NULL values, since the column data representation doesn’t provide a way to directly represent NULL values. The column data field is a packed array of the actual data values for the row. Each type has a different serialization format, which is discussed more in the next section. The last Rows event should set the End of Statement flag in the flags field so that that replica knows the transaction is complete.
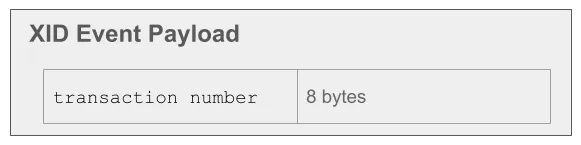
The final event in the sequence is an XID event, which marks the end of the transaction. This event is very simple, and only includes a transaction number.
Type Serialization#
One of the key parts of the replication protocol is how row data is serialized within Rows events. The MySQL binary log generally uses the same serialization formats that MySQL uses internally, which makes it easy and efficient for MySQL to read and write data from the binary log, since it doesn’t need to be deserialized and then serialized into a different format.
In general, the MySQL data type serialization formats are pretty straightforward and optimized for storage space efficiency. For example, an INT field is serialized as a signed 4-byte integer, with the bytes laid out in little endian order (Dolt’s binlog integerSerialization implementation). VARCHAR fields are serialized as a length-encoded string, with a small optimization for space efficiency – the length data is encoded as a single byte if the VARCHAR field was defined with a size of 255 or less, otherwise it uses two bytes to encode the value’s length (Dolt’s binlog stringSerializer implementation).
Other types are slightly more complex to serialize, such as JSON fields. MySQL’s JSON serialization format is a custom binary format that has optimizations for space efficiency, although that space efficiency can come at the cost of serialization efficiency. For example, MySQL’s internal binary JSON format uses either a “small” format or a “large” format for each map and array in the JSON doc. The small format uses two byte unsigned integers to represent the count of elements and the offset positions, whereas the large format uses four byte unsigned integers. The challenge with this format is that the serialized size of the data determines whether to use the small or large format – if the serialization size is too large to represent offsets in two bytes, then the large format must be used. However, the serialized size isn’t know until the data is serialized and depends not only on the size of the map or array, but the size of all the nested data in them, so it’s difficult to choose the best format up front. You can see in the MySQL codebase where maps and arrays are serialized first in the small format and then that work is thrown away if it is determined that the large format needs to be used.
One of the nice benefits of MySQL’s JSON format is that it enables faster lookups into the JSON document than if the JSON data was stored as a string and had to be reparsed into a JSON structure every time it was accessed. For example, if a query is extracting all the key values from a map in a JSON document, the binary format allows MySQL to quickly enumerate all the key strings in a map, without having to look at the rest of the JSON document or do any string parsing.
Wrap Up#
Thanks for taking this quick tour through some of the details of the MySQL binlog replication protocol. MySQL replication has been around for over two decades now and has proven to be a robust and reliable way to keep MySQL databases in sync. There’s a whole lot more to the MySQL replication protocol, but I hope this post has given you a good overview of how the protocol works and some of the details of the messages that are sent between a primary and replica.
If you’re interested in database replication, database development, or version controlled data, I hope you’ll join our Discord and come chat with us!