Dolt Storage: A Review


Storage of information is the bedrock of every Database in existence. The logical application concepts by which you store that information is where a lot of Database discussion occurs. In Dolt's case, we talk about Prolly trees a lot because they allow Dolt to have some of its key properties (structural sharing, fast diffs, etc). For many databases, Dolt included, the abstraction of how those data structures are written to disk is somewhat secondary. We are going to discuss how Dolt stores bytes on disk today, and highlight some the areas we are working on for improvement.
Core Access Pattern
As mentioned above, Prolly Trees get a lot of discussion in the Dolt blog. That's because they are really nifty, and they are a critical piece of Dolt's DNA. When you read those blogs, you'll see pictures like this:

It is important to remember that this is a representation of a structured object. The green entity is a list of addresses which point to other entities. All of these entities have addresses, such as t1ms3n (that Tim Sehn is clever), and the values are byte arrays. In Dolt, we call this byte array value a "Chunk". Every piece of information in a Dolt database is stored as Chunks.
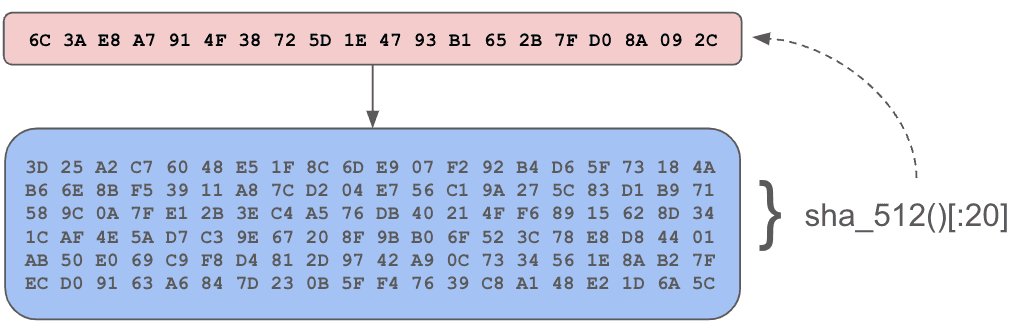
This is such a fundamental truth, I'll restate it in bold: Every piece of information in a Dolt database is stored as Chunks.
Chunks are content addressed byte buffers. Their address is the SHA512 checksum of the byte buffer truncated to 20 bytes. Content addressable systems have a few characteristics which make them interesting and useful:
- Strict Hierarchy of Information. For chunks which refer to other chunks, it's impossible to create chunks out of order because you can't refer to a chunk without its address. It's impossible to have cycles in your data.
- Chunk corruption can be detected. If you read a chunk from disk and its checksum doesn't match you know that something is wrong.
- Idempotent Persistence. If something on the write path fails and you need to write it again, there is no risk of corruption given (1) and (2).
Merkle Trees and DAGs depend on content addressed storage, and Dolt embraces them fully.
Given that all Dolt data is stored as Chunks, we want to access these chunks by two primary operations:
- Contains: We need a fast way to determine if a given storage file has the chunk in question. This comes up when we have multiple files and we don't actually know where the given chunk is. We need to be able to do this without accessing the disk excessively.
- Retrieve: Get the data out.
Both of these patterns have batch equivalents, but they aren't terribly interesting for today's discussion.
By keeping this level of simplicity, the storage system doesn't need to know anything about the contents of the Chunks. The serialization and deserialization of application data is performed at a layer above the storage system.
Noms Block Store
Noms is foundational to Dolt's existence, but that's a story for another time. The Noms team started out using a key value store system to store Chunks, but it proved to be suboptimal so they developed the Noms Block Store (NBS). That file format lives on as the only way to store Dolt data currently. If you prefer to read ASCII, all of these details can be found in source!
NBS stores Chunks in files which have the following structure:
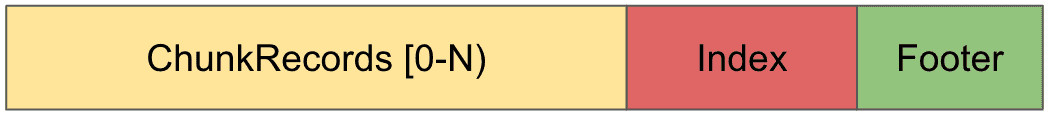
- Footer: Fixed size end of the file which tells us primarily how many Chunks there are stored in the entire file.
- Index: A deterministically sized (based on the footer) block of the file which contains all address information.
- ChunkRecords: zero-addressed Chunk Data.
The index is where most of the complexity resides. The index is made up of three sections:

- Prefix Map: This is the first 8 bytes of the Chunk addresses, coupled with an ordinal. The Prefixes are sorted so that we can do a binary search on the map to find a set of addresses which are in the file which have the given prefix. This binary search greatly reduces the search space needed to find the location the chunk requested. The ordinal is used to indicate the offset into Lengths and Suffixes.
- Lengths: This tracks the length of the Chunk at each ordinal.
- Address Suffixes: The address at that ordinal, minus the 8 bytes of the prefix which are redundant.
Contains
The algorithm to determine if the storage file contains a given address:
- Strip the first 8 bytes of the address, and call that the Prefix.
- Perform a binary search on the Prefix map, once one is found search the vicinity for additional matches.
- For the set of matched Prefixes, grab the Address Suffix at the associated Ordinal. This results in the suffix set.
- For the set of suffixes, compare each to the last twelve bytes of the address your are looking for.
- If one matches, the Chunk exists in the file.
Given that we are using SHA512 to calculate our addresses, we assume there is a decent distribution of addresses. Therefore, the time intensive portion of this algorithm is the binary search on the Prefix Map, which is O(log2(N)), where N is the number of chunks.
In the following example, there are 3 keys: ABC, LMN, and TUV. For each, the first character is considered the Prefix, and the second two are the Suffix.

Let's determine if the storage file contains ABC. First we need to read the footer, which tells us there are 3 chunks in this file. Using that, we calculate the offsets for the index from the end of the file. Using a seek operation, we load and parse this information for the duration of the process.

Now that we have the Prefix Map in memory, we pull the prefix, A off of our desired address ABC. The Prefix Map contains A,L,T, so doing a binary search we determine that the index 0 contains the prefix.

This example contains no collisions in the Prefix Map, but in the general case we find all matches, and gather the Ordinals. In this case, the Ordinal is 1. The Ordinal in the index into the Lengths and Suffixes.

Now, we compare the Suffix found at that location with the Suffix we are looking for, BC, and since they match, we know that this file contains the ABC Chunk.
Retrieve
To Retrieve the object requires additional steps. Using the Contains algorithm, we get the Ordinal of the Chunk found, then:
- Sum all values in the Lengths array up to the Ordinal. This is the byte offset into ChunkRecords.
- Perform a disk seek operation to the ChunkRecords portion of the file, and read the length of the chunk from that offset.
- Snappy Decompress the byte array, and you are done!
Note that step (6) has a O(N) operation in it, but we calculate those values at the time we load the Index initially. Loading the Index is a O(N) operation, but we only do it once.
To continue our example, to retrieve the value for ABC, using the Ordinal 1 from before, we find the sum of all lengths before the Ordinal in question. In our example, we don't have many things to sum up since our Ordinal is 1. I should have thought of that before I made these pretty pictures!

The goal of this step is to get the offset and length of the Chunk. By summing all of the lengths of Chunks which become before the one we care about, we get the offset. Then the length is simply the value in the Ordinal position. In our case, offset is 1, and length is 4.

The value for Chunk ABC is 44 61 74 61! Well, technically we'd need to decompress that, but let's leave that for another time. Looking up LMN and TUV is an exercise left to the reader.
To recap, here is a gif!
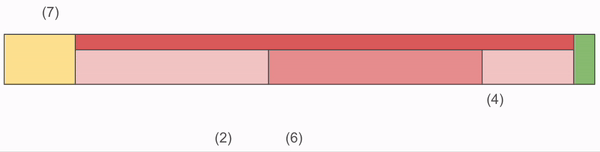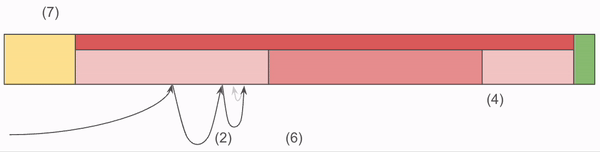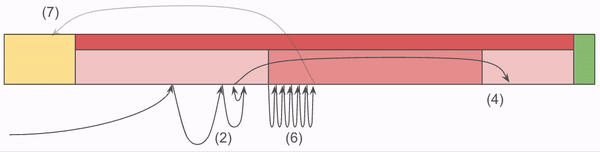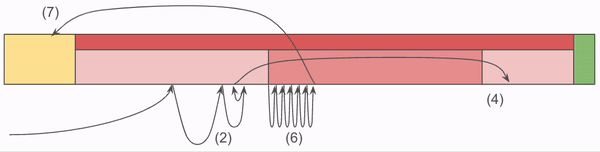
The critical piece here is that the Index does most of the heavy lifting. It's loaded into memory at server start up, and as a result we confine all of our lookup code to that memory. It's only after we've determined the full offset of the Chunk that we venture into that yellow block, which requires a disk read.
Limitations
Here are a couple things to consider:
- Improvements in Compression and Decompression. All objects in NBS are compressed with the Snappy compression algorithm. This was state of the art in the past, but there are better standards now. Just by using zStandard on all individual chunks, we could reduce total disk usage by 25%. That's nothin' to sneeze at.
- Chunks in isolation compress poorly. Many of the chunks we store in Dolt are highly similar, but individually include high entropy data and is virtually impossible to compress. NBS doesn't provide us any mechanism to group them together, which would result in much better compression. Next week, I'll blog about the wonders of Dictionary Compression, and how it's impacting our plans for storage. Stay tuned!
- O(log2(N)) is ok for contains, but we could do better with a Bloom Filter.
- The format doesn't have any notion of a format version aside from its magic number stored in the footer. This limits our flexibility in extending the format and maintaining backwards compatibility.
- We are forced to load the entire Index into memory before we can make use of it. These can get fairly large. For a 500Mb database which contains ~300K chunks, the index ends up being 9Mb.
What's Next
NBS has been very stable for a long time and it isn't generally a performance bottleneck. Disk space is pretty cheap, and optimizing how we store bytes on disk just hasn't been where we have needed to focus our energy. That is changing though. We know there is a lot of room for improvement in our space usage, and as our users are storing more data with us their histories are becoming longer. Optimizing our storage will come first in the form of dolt gc being able to generate storage files which are smaller by as much as 50%. In order to do that though, we'll need a new storage format. We'll share more next week, but if you can't wait and want to talk to us on Discord, please do!
