
Introduction#
We’re building Dolt, the world’s first version-controlled SQL database. Dolt is MySQL compatible, but many of our prospective customers wanted a Postgres-compatible version instead, so we have been hard at work building DoltgreSQL.
The first prospective DoltgreSQL customer to reach out to us wants to continue using Postgres for their primary database server, but get diffs of all their changes in Doltgres. So we talked it over with them and decided that Postgres’s logical replication would be the best fit for this functionality, and started building it. A few weeks later, DoltgreSQL’s replicate-from-Postgres feature is almost ready for production use, and you’ll be able to try it out in the next release of the product.
This blog discusses what we learned building this feature, and walks you step-by-step through how to build a replication system consuming Postgres’s logical replication protocol in Go. We’ll be using the jackc/pglogrepl library to consume and send messages with the Postgres primary, but most of the lessons generalize to other clients as well.
What is logical replication?#
Logical replication is one of two modes of replication supported by Postgres. Both consume the write-ahead log (WAL) produced by the primary database, which is where Postgres serializes all data it writes to disk. The WAL is very low-level binary data containing information related to physical blocks on disk that Postgres wrote as a result of write operations. It is difficult to interpret if you’re not a Postgres database server yourself. The two types of replication Postgres supports are:
- Physical replication copies the bytes of the WAL directly from primary to replica. It’s really only appropriate for replicating between a primary and replica running the same binary release of Postgres.
- Logical replication interprets updates to the WAL on the primary database, then sends them to
the replica as a series of tuple messages describing an
INSERT,UPDATE, orDELETEoperation. Because it abstracts away the physical serialization of the WAL, it can be used to replicate between different versions of Postgres, such as different major releases or even operating systems. Or, as we’ll see, to replicate to a totally non-Postgres system.
What we found is that, while it’s certainly possible (even easy) to receive replication messages from Postgres, interpreting and applying them correctly in the face of concurrent transactions and client crashes is quite challenging, and requires a pretty deep understanding of how the protocol works.
Let’s dig in.
Properties of a good replication system#
Before we discuss the details of our replication implementation, we should start by defining design goals for how a reliable replication system should behave. These may seem obvious, but it’s very easy to write a system that accidentally omits one of these critical properties in some circumstances. We must always keep them front of mind while writing any replication system, and have tests thoroughly exercising them in the face of a variety of scenarios.
- The system must not miss any updates. Every tuple change sent by the primary must be durably recorded by the replica.
- The system must not apply any update more than once. Every tuple update must be applied exactly once.
- Changes in a transaction must be applied atomically. The primary sends each tuple update in its own message, but none of them must become visible to clients of the replica until the corresponding transaction on the replica has been committed.
- The system must be resilient to sudden crashes. A replication process could die at any point during execution, and the above properties must still be preserved.
- The system must inform the primary about its progress. Admins on the primary database can run queries to determine how far behind each replica is. This information doesn’t need to be exactly up to date, but if it’s too far behind the primary will be prevented from performing necessary cleanup on older WAL files that are not actually needed any longer.
In addition to these critical requirements, a replication system may also implement some quality-of-life features. These are nice-to-haves.
- Easy to cold-start. It should be possible to start a new replica with no downtime on the primary and a minimum amount of effort on the replica.
- Easy to recover from errors. For a variety of reasons, it may not be possible to apply every change on the primary to the replica. When this happens, it should be easy to find the error and restart the process to continue replication from where the error first occurred.
Now that we understand how our system must behave, lets look at the logical replication protocol messages sent by a Postgres primary and discuss how to handle them.
Postgres logical replication message flow#
Like many complex systems, the logical replication system on Postgres is assiduously documented in the fine details but profoundly lacking in the big picture. That is to say: it’s easy enough to learn how many aspects of the system work, but very difficult to understand how they should fit together to achieve some goal. In our case, in addition to reading many (many!) pages of documentation, it was also necessary to write and test various prototypes to understand the behavior of the primary in various scenarios.
Logical replication is a two-way process in which the primary and the replica must both behave as expected to prevent incorrect behavior. We discovered these properties through trial and error, but hopefully someone reading this in the future will be able to use our learning process as a shortcut in their own implementation.
Creating a publication and a slot#
Postgres requires all replicas to register themselves ahead of time in a two-step process.
First, create a publication on the primary. A publication tells the primary which tables you want to replicate. You can also replicate all tables if you want. As a database admin, run the following SQL on the primary:
CREATE PUBLICATION pub1 FOR ALL TABLES;"
CREATE PUBLICATION pub2 FOR TABLE t1;"
...Next, create a replication slot on the primary. Each publication can have multiple independent subscribers, and each needs a replication slot. The total number of slots is limited by the primary server and can be changed via configuration. As a database admin, run the following SQL on the primary:
CREATE_REPLICATION_SLOT slot1 LOGICAL pgoutput;The pglogrepl library has a convenience method to do this for you:
pglogrepl.CreateReplicationSlot(context.Background(), conn.PgConn(), "slot1", "pgoutput", pglogrepl.CreateReplicationSlotOptions{})Now that we have a publication and a slot, we can begin replication.
Starting replication#
The rest of the replication protocol takes place on a single connection. Messages flow back and forth between the primary and the replica.
To begin, open a connection to the primary and run the START_REPLICATION command like so:
START_REPLICATION SLOT slot1 LOGICAL 0/0 (proto_version '2', publication_names 'pub1', messages 'true', streaming 'true');Again, plgogrepl has a wrapper you can use to work in an object-oriented style:
conn, err := pgconn.Connect(context.Background(), "postgres://postgres:password@127.0.0.1:5432/postgres?replication=database")
if err != nil {
return nil, err
}
pluginArguments := []string{
"proto_version '2'",
fmt.Sprintf("publication_names '%s'", publicationName),
"messages 'true'",
"streaming 'true'",
}
// The LSN is the position in the WAL where we want to start replication, but it can only be used to skip entries,
// not rewind to previous entries that we've already confirmed to the primary that we flushed. We still pass an LSN
// for the edge case where we have flushed an entry to disk, but crashed before the primary received confirmation.
// In that edge case, we want to "skip" entries (from the primary's perspective) that we have already flushed to disk.
log.Printf("Starting logical replication on slot %s at WAL location %s", slotName, lastFlushLsn+1)
err = pglogrepl.StartReplication(context.Background(), conn, slotName, lastFlushLsn+1, pglogrepl.StartReplicationOptions{
PluginArgs: pluginArguments,
})
if err != nil {
return nil, err
}
return conn, nilWe’ll return to details about the lastFlushLsn in a bit.
Note that the connection you execute this command on must include a replication=database query
param. If you forget to include this query param, the START_REPLICATION command will actually
fail with a syntax error. Invoking a separate parser syntax depending on the presence of a query
param is a bizarre design decision on the part of Postgres that makes errors needlessly difficult to
debug, so be aware of it.
If the START_REPLICATION command succeeds, your connection is in replication streaming mode, and
replication messages will flow to your replica. You’re expected to reply to them appropriately.
Replication message flow#
The primary sends one of two top-level messages over and over:
- Primary keepalive message: This is the idle message that the primary sends whenever there’s nothing else happening. It contains the current server time and position in the WAL, and a boolean requesting a reply. The replica should reply as soon as possible when requested to avoid disconnection.
- XLogData: This message bundles another logical message within itself, containing the actual replication instructions. It also includes some metadata about the message, such as the server time and WAL position of this message.
Using pglogrepl, we can receive the next replication message like so:
rawMsg, err := primaryConn.ReceiveMessage(ctx)
msg, ok := rawMsg.(*pgproto3.CopyData)
if !ok {
log.Printf("Received unexpected message: %T\n", rawMsg)
return nil
}
switch msg.Data[0] {
case pglogrepl.PrimaryKeepaliveMessageByteID:
pkm, err := pglogrepl.ParsePrimaryKeepaliveMessage(msg.Data[1:])
if err != nil {
log.Fatalln("ParsePrimaryKeepaliveMessage failed:", err)
}
return handleKeepalive(pkm)
case pglogrepl.XLogDataByteID:
xld, err := pglogrepl.ParseXLogData(msg.Data[1:])
if err != nil {
return err
}
err := processXdMessage(xld, state)The replica replies to these messages with a single message in all cases: the standby status update message. This message contains three pieces of vital info used to synchronize the replica in case of connection loss or unexpected restart:
- Last written WAL position
- Last flushed WAL position
- Last applied WAL position
Using pglogrepl, you can send the status update like this:
err := pglogrepl.SendStandbyStatusUpdate(context.Background(), primaryConn, pglogrepl.StandbyStatusUpdate{
WALWritePosition: lastWrittenLSN + 1,
WALFlushPosition: lastWrittenLSN + 1,
WALApplyPosition: lastReceivedLSN + 1,
})The primary server tracks these values and will use them to re-establish replication at the right WAL position on a restart. They are also used to inform any admins of how far this replica is behind the primary (replication lag). See the following sections for details on the meanings of the WAL parameters in this message.
The most important messages are the XLogData messages, which contain actual tuple data changes.
Processing XLogData messages#
Finally, we arrive at the meat of the problem: processing data updates and applying them to our own
replica. Each XLogData message wraps one other logical message for us to decode and interpret. But
here too Postgres adds an additional layer of complexity, sending two kinds of wrapped logical
messages:
- Metadata messages that describe the tables being replicated and their types. The most important is the Relation message, which gives information about the schema of tables being replicated. You may also receive Type messages, which identify custom types including their names and OIDs.
- Data messages that describe the changes to the WAL being replicated. In addition to messages
corresponding to
INSERT,UPDATE, andDELETEstatements, the primary also sends Begin messages, which mark the start of a set of tuple changes committed in a transaction, and a Commit message, which ends the set.
So, after beginning replication, you’ll begin receiving XLogData messages from the primary. These
follow a reliable sequence:
- First, any Relation messages for the tables being replicated. Depending on what you’re trying to do, you probably want to parse these messages and remember the schemas they describe.
- Then, for each committed transaction, you’ll receive a Begin message, which includes the WAL position of the eventual commit. Only transactions that were successfully committed to the primary are sent to logical replicas: you won’t even receive a Begin message that corresponds to a transaction that was rolled back.
- Next, for every row that changed as a result of this transaction, you’ll receive one of: an Insert message; an Update message; or a Delete message. Each of these correspond to their equivalent SQL statement and have enough information to apply them accordingly. Note that these are not the statements executed on the primary as part of each transaction: they are logical updates to a single row that occurred as a result of whatever statements were executed.
- Finally, you’ll receive a Commit message indicating the previously received set of tuple updates should be committed in a transaction. Unlike the Begin message, the Commit message doesn’t include any WAL position metadata.
This flow is best illustrated with an example.
WAL data and replication example#
To understand how messages flow from the primary to the replica, it helps to understand how changes
in Postgres’s write-ahead log (WAL) get translated into replication messages. Postgres writes all
data changes from queries into the WAL as they happen. Each record in the WAL contains
physical-data-level changes to tuples, as well as metadata such as the transaction responsible for
that change. Crucially, entries in the WAL are written throughout a transaction’s lifecycle, but do
not become permanent or visible to other transactions until that transaction is successfully
committed. The COMMIT is itself a message written to the WAL as well, and makes all the data
changes that were a part of that transaction permanent.
You can picture the WAL as a series of data updates coming from their various transactions. Under concurrency, these entries can and will be interleaved. Here we see statements being executed by three concurrent transactions (color-coded red, blue, and green) and their respective WAL entries.
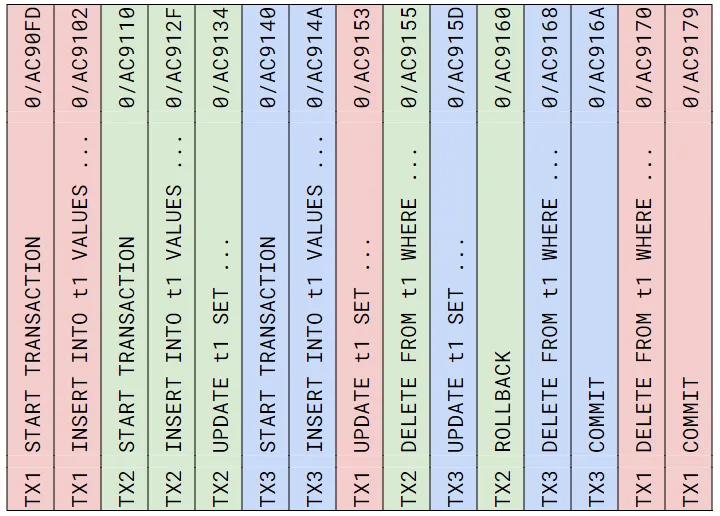
When Postgres replicates these transactions to logical subscribers, it does so on a per-transaction
basis, in the order that each transaction commits. For each transaction, the subscriber will receive
a Begin message, followed by one or more tuple change messages, and concluding with a Commit
message. Unlike in the physical WAL, messages for different transactions are not interleaved. For
the above WAL example, the replication messages received by the subscriber will look something like
this:
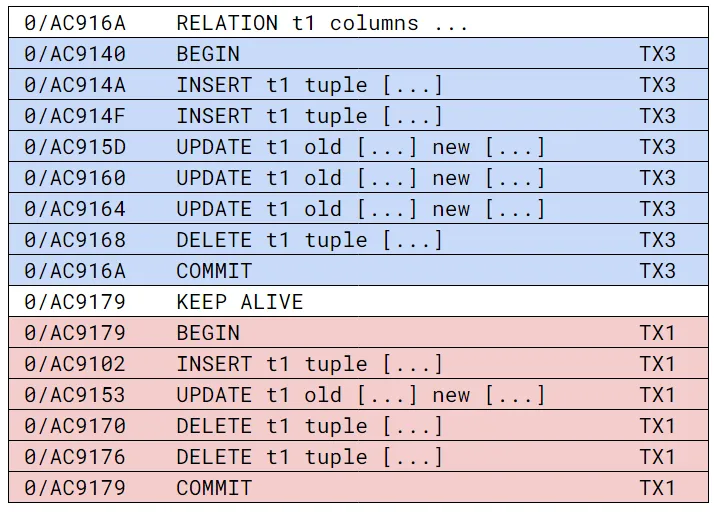
There are a few things to note here:
TX3(the green one) is not replicated, since it was rolled back.TX2comes first since it committed first, even thoughTX1started writing WAL entries first.- The WAL position of each tuple is behind the eventual
COMMIT’s WAL position. TheKeepalivemessage sends the current WAL of the primary as a whole, which is typically ahead of the tuple messages being received. - Each replication statement corresponds to a single tuple that was changed as a result of an
INSERT,UPDATE, orDELETEstatement. So there may be multiple tuple replication messages sent for each statement executed on the primary.
Next, let’s look at some example Go code for processing the tuple data we get in XLogData
messages.
Processing tuple data#
Using pglogrepl, we can process these messages like this:
func (r *LogicalReplicator) processMessage(
xld pglogrepl.XLogData,
state *replicationState,
) (bool, error) {
walData := xld.WALData
logicalMsg, err := pglogrepl.ParseV2(walData, state.inStream)
if err != nil {
return false, err
}
log.Printf("XLogData (%T) => WALStart %s ServerWALEnd %s ServerTime %s", logicalMsg, xld.WALStart, xld.ServerWALEnd, xld.ServerTime)
state.lastReceivedLSN = xld.ServerWALEnd
switch logicalMsg := logicalMsg.(type) {
case *pglogrepl.RelationMessageV2:
state.relations[logicalMsg.RelationID] = logicalMsg
case *pglogrepl.BeginMessage:
if state.lastWrittenLSN > logicalMsg.FinalLSN {
log.Printf("Received stale message, ignoring. Last written LSN: %s Message LSN: %s", state.lastWrittenLSN, logicalMsg.FinalLSN)
state.processMessages = false
return false, nil
}
state.processMessages = true
state.currentTransactionLSN = logicalMsg.FinalLSN
log.Printf("BeginMessage: %v", logicalMsg)
err = r.replicateQuery(state.replicaConn, "START TRANSACTION")
case *pglogrepl.CommitMessage:
log.Printf("CommitMessage: %v", logicalMsg)
err = r.replicateQuery(state.replicaConn, "COMMIT")
if err != nil {
return false, err
}
state.processMessages = false
return true, nil
case *pglogrepl.InsertMessageV2:
return r.handleInsert(logicalMsg)
case *pglogrepl.UpdateMessageV2:
return r.handleUpdate(logicalMsg)
case *pglogrepl.DeleteMessageV2:
return r.handleDelete(logicalMsg)
case *pglogrepl.TruncateMessageV2:
log.Printf("truncate for xid %d\n", logicalMsg.Xid)
case *pglogrepl.TypeMessageV2:
log.Printf("typeMessage for xid %d\n", logicalMsg.Xid)
case *pglogrepl.OriginMessage:
log.Printf("originMessage for xid %s\n", logicalMsg.Name)
case *pglogrepl.LogicalDecodingMessageV2:
log.Printf("Logical decoding message: %q, %q, %d", logicalMsg.Prefix, logicalMsg.Content, logicalMsg.Xid)
case *pglogrepl.StreamStartMessageV2:
state.inStream = true
log.Printf("Stream start message: xid %d, first segment? %d", logicalMsg.Xid, logicalMsg.FirstSegment)
case *pglogrepl.StreamStopMessageV2:
state.inStream = false
log.Printf("Stream stop message")
case *pglogrepl.StreamCommitMessageV2:
log.Printf("Stream commit message: xid %d", logicalMsg.Xid)
case *pglogrepl.StreamAbortMessageV2:
log.Printf("Stream abort message: xid %d", logicalMsg.Xid)
default:
log.Printf("Unknown message type in pgoutput stream: %T", logicalMsg)
}
return false, nil
}We don’t handle all the logical replication events possible, just the ones we need to. What you do
with these messages is of course up to you. We’re replicating them into another database system, so
we want to transform the tuple data into equivalent SQL statements. The one for INSERT looks like
this:
func (r *LogicalReplicator) handleInsert(
xld pglogrepl.XLogData,
state *replicationState,
) (bool, error) {
if !state.processMessages {
log.Printf("Received stale message, ignoring. Last written LSN: %s Message LSN: %s", state.lastWrittenLSN, xld.ServerWALEnd)
return false, nil
}
rel, ok := state.relations[logicalMsg.RelationID]
if !ok {
log.Fatalf("unknown relation ID %d", logicalMsg.RelationID)
}
columnStr := strings.Builder{}
valuesStr := strings.Builder{}
for idx, col := range logicalMsg.Tuple.Columns {
if idx > 0 {
columnStr.WriteString(", ")
valuesStr.WriteString(", ")
}
colName := rel.Columns[idx].Name
columnStr.WriteString(colName)
switch col.DataType {
case 'n': // null
valuesStr.WriteString("NULL")
case 't': // text
// We have to round-trip the data through the encodings to get an accurate text rep back
val, err := decodeTextColumnData(state.typeMap, col.Data, rel.Columns[idx].DataType)
if err != nil {
log.Fatalln("error decoding column data:", err)
}
colData, err := encodeColumnData(state.typeMap, val, rel.Columns[idx].DataType)
if err != nil {
return false, err
}
valuesStr.WriteString(colData)
default:
log.Printf("unknown column data type: %c", col.DataType)
}
}
err = r.replicateQuery(state.replicaConn, fmt.Sprintf("INSERT INTO %s.%s (%s) VALUES (%s)", rel.Namespace, rel.RelationName, columnStr.String(), valuesStr.String()))
if err != nil {
return false, err
}
}Keeping your place in the WAL and informing the primary of your status#
There’s one final important detail that you need to be aware of when processing replication messages from the Postgres primary: you must locally track the last location in the primary’s WAL that you have flushed to disk. You have to persist this somewhere durably, preferably with the same durability guarantees as wherever you’re replicating the data updates, and atomically with the data updates themselves. In a pinch, you could use a normal file to track this piece of data, but then you have a data race. If your process dies between flushing tuple data to disk and flushing the WAL location to disk, on a restart you’ll either begin processing a duplicate message, or skip a message, depending on the order of the writes.
In our implementation, the processMessage method returns a boolean value indicating whether the
logical message was a Commit, which corresponds to us committing our own transaction. If it was, we
also store the last WAL position of the transaction we just committed, which we originally received
from a Begin message from the primary.
committed, err := r.processMessage(xld, state)
if err != nil {
return handleErrWithRetry(err)
}
if committed {
state.lastWrittenLSN = state.currentTransactionLSN
log.Printf("Writing LSN %s to file\n", state.lastWrittenLSN.String())
err := r.writeWALPosition(state.lastWrittenLSN)
if err != nil {
return err
}
}Somewhat confusingly, Postgres also durably tracks each subscriber’s last confirmed flush location in the WAL, and it’s tempting to believe you can just let Postgres track this state for you. But that solution is not workable, for the same reason you can get data races when using a normal file to track the WAL location. It’s even worse in the case of Postgres, because now the state and failure modes are split across two nodes in the distributed system.
It’s important to periodically update the Postgres primary on your replication standby’s status, because it keeps track of which WAL files are safe to recycle. Over time, a primary with subscribers who don’t update their flushed position in the WAL will suffer file bloat and potentially degraded performance in some scenarios.
The message to update the primary contains three fields for WAL positions:
Int64
The location of the last WAL byte + 1 received and written to disk in the standby.
Int64
The location of the last WAL byte + 1 flushed to disk in the standby.
Int64
The location of the last WAL byte + 1 applied in the standby.Note the + 1 in all these field descriptions. Postgres expects to you add 1 to every WAL location
you receive or write in order to get the correct behavior. The docs don’t make this 100% clear, but
the most important of these fields is the second one (flushed to disk), since that’s the location
Postgres uses when resuming replication streaming after an interruption. It’s really important to
read the fine print in the START_REPLICATION
command
about how this works:
Instructs server to start streaming WAL for logical replication, starting at either WAL location XXX/XXX or the slot’s confirmed_flush_lsn (see Section 54.19), whichever is greater. This behavior makes it easier for clients to avoid updating their local LSN status when there is no data to process. However, starting at a different LSN than requested might not catch certain kinds of client errors; so the client may wish to check that confirmed_flush_lsn matches its expectations before issuing START_REPLICATION.
In other words, it’s possible to skip ahead of the WAL location you last confirmed flushed to the
primary, but impossible to rewind the stream. Once you send a Standby status update message with a
particular flush location, the primary will never send you another replication event before then.
You also can (and should) periodically update the primary with the last WAL position you received,
including the one included in a keepalive message. Just make certain to not send a flushed WAL
location that you haven’t actually flushed.
Our implementation loads the last flushed WAL location at startup and uses that in its
START_REPLICATION message.
lastWrittenLsn, err := r.readWALPosition()
if err != nil {
return err
}This behavior handles the edge case where our replica flushes a transaction to disk but the process
dies before telling Postgres about it. In our testing we also found that even if you successfully
send a Standby update message with the last flushed WAL position, Postgres might not durably
persist it if the connection is interrupted after receipt. Our implementation is very conservative
about these edge cases, which is the reason for the processMessages bool we track in our state
struct. From what we can tell, the replication process on the Postgres primary is fundamentally
asynchronous, and in certain failure modes it’s possible to be sent messages from before the WAL
position you asked for. Our implementation just skips all such messages until we see a Begin
message past our last known flush point.
Conclusion#
DoltgreSQL is free and open source, so go check it out if you’re interested in replicating your PostgreSQL primary to a data store with built-in diff capabilities, or if you’re building your own Postgres replication solution and want a working example.
Have questions about DoltgreSQL or Postgres replication? Join us on Discord to talk to our engineering team and meet other Dolt users.