
Dolt is a SQL database with MySQL’s syntax and Git’s versioning semantics. Dolt is run as a service, and when things go wrong we prefer SQL errors to crashed servers.
This was the basic premise behind Brian’s painstaking rewrite of Noms panics a few years ago. Noms was riddled with panic error handling that frequently caused outages:
res, err := function(); if err != nil {
panic(err)
}Today, all of Dolt’s application code carefully returns errors to users. An error in the storage or execution engines is passed through several dozen functions before reaching the user:
if err := func(); err != nil {
return err
}But panics have their place too. I have come to resurrect the the old ways. Time to panic.
Setup#
We will benchmark the go-mysql-server (GMS) validation rules with error passing compared to a panic/recover workflow outlined in this conference talk from Cockroach Labs. Validators are convenient for benchmarking this strategy because they return the first error or no error.
As an example, here is an abbreviated version of a validator rule our new team member Nick added in his first week:
func validateStar(ctx *sql.Context, a *Analyzer, n sql.Node, scope *Scope, sel RuleSelector) error {
var err error
transform.Inspect(n, func(n sql.Node) bool {
if er, ok := n.(sql.Expressioner); ok {
for _, e := range er.Expressions() {
// An expression consisting of just a * is allowed.
if _, s := e.(*expression.Star); s {
return false
}
sql.Inspect(e, func(e sql.Expression) bool {
if err != nil {
return false
}
switch e.(type) {
case *expression.Star:
err = analyzererrors.ErrStarUnsupported.New()
return false
return true
}
})
}
}
return err == nil
})
return err
}Inspect walks the tree, invoking the callback on every
node/expression. The callback return value bool indicates whether a
walk should keep searching or to wind back up the stack.
Our benchmark will run 16 of these in a loop:
func validate(ctx *sql.Context, n sql.Node) error {
for _, v := range validationRules {
_, _, err := v(ctx, nil, n, nil, nil)
if err != nil {
return err
}
}
return nil
}Here is the same code with a panic:
func validateStar2(ctx *sql.Context, a *Analyzer, n sql.Node, scope *Scope, sel RuleSelector) {
transform.Inspect(n, func(n sql.Node) bool {
if er, ok := n.(sql.Expressioner); ok {
for _, e := range er.Expressions() {
// An expression consisting of just a * is allowed.
if _, s := e.(*expression.Star); s {
return false
}
sql.Inspect(e, func(e sql.Expression) bool {
_, ok := e.(*expression.Star)
if ok {
panic(analyzererrors.ErrStarUnsupported.New())
}
return true
})
}
}
return true
})
}We still walk all of the nodes/expressions in the plan. But when we find
an error, we just panic. Here’s how the second validators are
benchmarked:
func validate2(ctx *sql.Context, n sql.Node) (err error) {
defer func() {
if r := recover(); r != nil {
err = r.(error)
}
}()
for _, v := range validationRules2 {
v(ctx, nil, n, nil, nil)
}
return
}The deferred recover() is the key here. A panic with no recovery
crashes the application. In validate2 above, any panic in a nested
function jumps to the recovery block. Inside the recovery block we
catch, cast, and set the return err. The panic is opaque to everything
outside of our validate2 function. For more details see the Golang
docs.
Results#
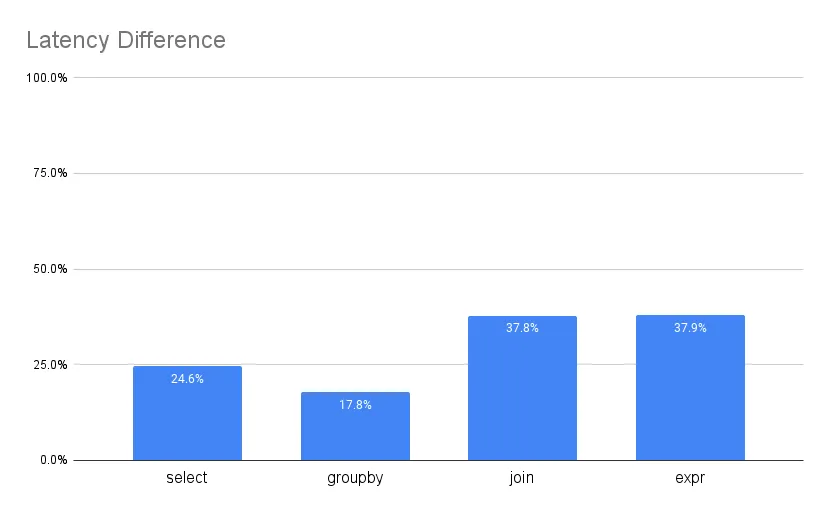
Below are benchmark latencies for validating the sample of queries below. The ns/op y-axis reflects an average of amount of time spent validating a query.

As you can see, panic performs better across the board and in some cases is almost 40% faster!
Here are the handful of queries tested, for context.
-- select
select x from xy
-- group by
select x, count(x), y from xy group by x limit 1 offset 1
-- join
select a1.x, a2.x, a3.x, a4.x
from a1 xy
join a2 on a1.x = a2.x
join a3 on a1.x = a3.x
join a4 on a1.x = a4.x
-- expr
select
(
(x = 1 AND y > 1) OR
(x < 5 AND -20 < y < 20)
) AND
(-10 < y < 10)
from xy;I was expecting a 5-10% difference, but the results are surprisingly strong. Semantic validation is 20-40% faster for small well-formed queries when we eliminate the calling convention in our validators.
Why is it faster?#
Errors increase the number of return arguments and if statements for every function in the call stack. Return arguments translate to machine code for shuffling return arguments to and from registers during the calling convention. Unused branches do not slow our cycles per second, but they reduce the useful capacity of the code cache. On the happy path, panics drop the calling conventions. The unhappy path experiences the same speedup but avoids walking up the call stack. The panic jumps straight to the recover placed at the root of our validator.
One interesting follow-up would compare the assembly between the two versions. We measured the practical performance for a handful of queries, but I am also interested in how many lines of machine code we eliminated in the source.
Is this actually a good idea? (don’t panic yet)#
Before peppering the execution engine with potentially explosive bits of code, it is useful to trade-off the non-performance considerations.
Developers editing or adding panic validators need to align with a new set of expectations. Panics require a new code style guide. Being aware of different parts of the code base using a specific style adds overhead. But I think it is low risk for something like a validator, where the code is grouped and standardized.
In fact, it is arguably easier and safer to write the panic style. The panic is a GOTO jump to short-circuit return an error. The alternative saves errors to a temporary variable that we hope is not modified winding up the stack. It is also easy to “drop errors” in passthrough subroutines. An error is dropped when a function fails to catch and surface an error from a nested function. Lastly, removing error checks and temporary variables is more concise and easier to maintain.
Panics overlay poorly with errors in the same section of code. The nature of panics blows away application logic between the source and recover. It is impossible for intermediate functions to switch on error type if a panic jumps over its head.
A good rule of thumb is that interfaces should use errors to communicate
by default. It is unreasonable and poor practice for a producer to
require a consumer to recover(). Errors let application logic switch on error
types in a safe and convenient way. Panics can safely be used in sections of
code where errors have no impact on the intervening logic.
Summary#
We have walked through an example of how panic/recovery workflows improve performance and code organization for our engine’s validation rules. Panics are a tool with uses and drawbacks, and there are a few things to keep in mind:
-
Panic/recover is faster than chains of error returns.
-
Modules with simple logic can benefit from using panics to short-circuit return pathways.
-
Interfaces should use errors to communicate. Expecting a consumer to mix and match panics/errors is unreasonable and error (panic) prone.
We will experiment more with integrating this workflow into our execution engine in the coming months. In the meantime, if you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!