
Dolt is a MySQL-compatible database with Git-like features. DoltHub is GitHub for Dolt. Hosted DoltDB is AWS RDS for Dolt. Both DoltHub and Hosted come with a UI to help visualize data and track changes, while also providing seamless collaboration among team members via pull requests. The Hosted SQL workbench is modeled after the DoltHub database page.
This blog will discuss the differences between these two products, their use cases, why and how these differences drove some changes to the workflows on the Hosted workbench, and other new workbench-driven Dolt features.
DoltHub vs Hosted#
There are two ways to use Dolt. You can run Dolt offline, treating data and schema like source code in the same way you’d use Git. Or you can run Dolt online, like you would PostgreSQL or MySQL. DoltHub, similar to GitHub, is for collaborating offline on Dolt databases, while Hosted is for running online production databases.
DoltHub is a hosted Dolt remote. It
uses doltremoteapi, a service that wraps Dolt’s storage layer’s interface, which allows
the website to interact with Dolt databases that are stored in AWS S3. When you view a
page on DoltHub, its API asks doltremoteapi for its storage layer interface, and uses
that to query Dolt data. When you make a change on DoltHub it’s not automatically
reflected in other remotes. You must use clone, push, pull, or fetch to sync
different copies of your database.
Hosted is a cloud-hosted, running Dolt database that you can connect to with any MySQL client over the internet. The SQL workbench on Hosted uses a Node.js MySQL client to connect to a deployment’s running SQL server, utilizing Dolt’s SQL version control features to display data in a similar to way to DoltHub. But unlike DoltHub, changes you make from a connected client are reflected immediately in other clients without any manual syncing.
Which Dolt should I use?#

We have a few different products depending on your use case for Dolt.
Looking for GitHub-like asynchronous collaboration? Or interested in creating and sharing open data, on your own or through one of our data bounties? DoltHub is for you.
Want the DoltHub experience, but on your local network or desktop? Check out DoltLab.
Need a fully-managed cloud hosted solution for Dolt, similar to AWS RDS? You want Hosted Dolt.
No matter your use case, we have a Dolt for you. What all these products have in common is you get a Dolt database with the full power of version control. They come with a UI that makes visualizing data, tracking changes, and collaborating easy. While we had initially decided to create an identical user experience for DoltHub/DoltLab and the Hosted workbench, we realized we should differentiate them a little bit based on the unique features that make each product right for their use case.
Just an online girl, livin’ in an offline world#
Dustin is currently working on using Dolt (via Hosted) as our production database for the DoltHub website. Dolt wasn’t ready to be used in production when we initially launched dolthub.com back in 2019, but who are we to sell Dolt as a production database without using it ourselves?
We started using the workbench more heavily for testing and debugging while replacing our Postgres database with Dolt for our development site. This was a different use case than we originally built the workbench for, which was a DoltHub-like interface for non-admins to make changes in an indestructible and tractable way.
DoltHub achieves this through workspaces, or a “staging area” for changes made on DoltHub. Every modification query run from the DoltHub SQL console creates a workspace, where you can view the results of changes without affecting the state of the database. When you’re satisfied with your changes you can commit them to a branch or create a pull request. If you’re not satisfied with your changes, you can delete the workspace without any repercussions.
Unlike DoltHub, you can see working sets when you connect to a SQL server, which can also be seen as a “staging area” for Dolt. If we were going to copy the workspaces workflow for the Hosted workbench, it didn’t make sense to have two staging areas. So we chose the workspace model and decided not to show working sets in the Hosted workbench.
While this model worked for the initial workbench use case we had in mind, where every change from the workbench would result in a commit, we quickly realized that not showing uncommitted changes was the wrong call for the nature of an online product. The workbench needed to reflect the current state of the data, whether that data had been committed or not.
Leaning into the online Hosted experience#
We pivoted our workbench model and removed workspaces. Hosted is an online product and it
made more sense to model the workbench after a more standard SQL workbench, but with the
added version control and collaboration features that make Dolt unique and cool. Now
you’ll see working sets in the workbench. You can make changes without creating commits
and view diffs between WORKING, STAGED, and HEAD revisions using the workbench.
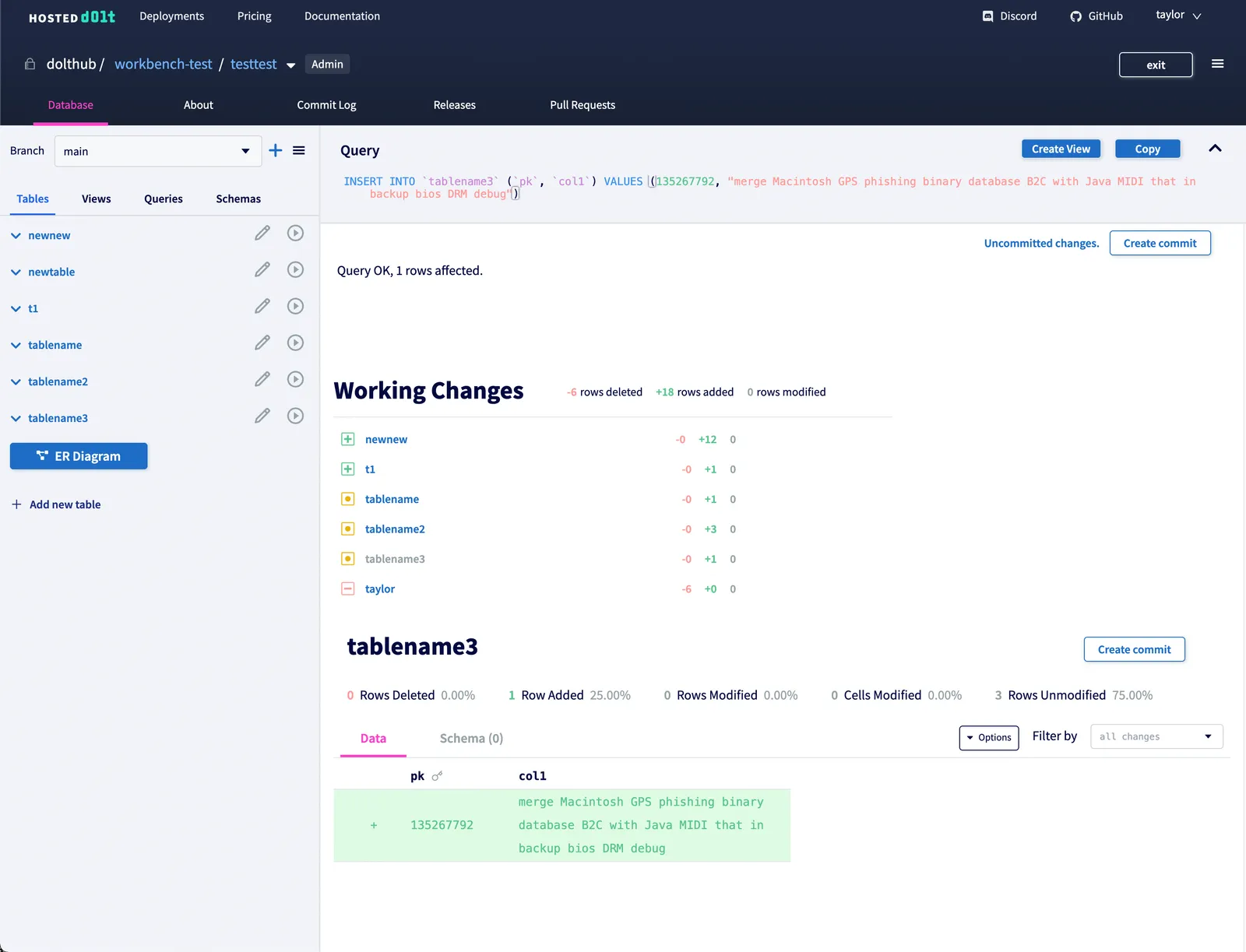
While this moves the Hosted workbench model away from DoltHub a little bit, it still has
features that make DoltHub easy to use and collaborate, like cell history, diffs, and pull
requests. We have plans to make the branch and merge workflows more discoverable, as well
as add a collaborator role that only allows changes to the main branch via a pull
request workflow. This will be ideal for any non-admin users who require more oversight as
they’re making changes.
Other fun workbench-driven Dolt updates#
In order to get working set diffs in the workbench working, we had to refactor some of our
diff logic. This resulted in a new Dolt table
function:
dolt_diff_summary
(the old dolt_diff_summary was renamed to
dolt_diff_stat).
Jennifer also added a
dolt_patch
table function, which we can now use for schema patches.
dolt_diff_stat#
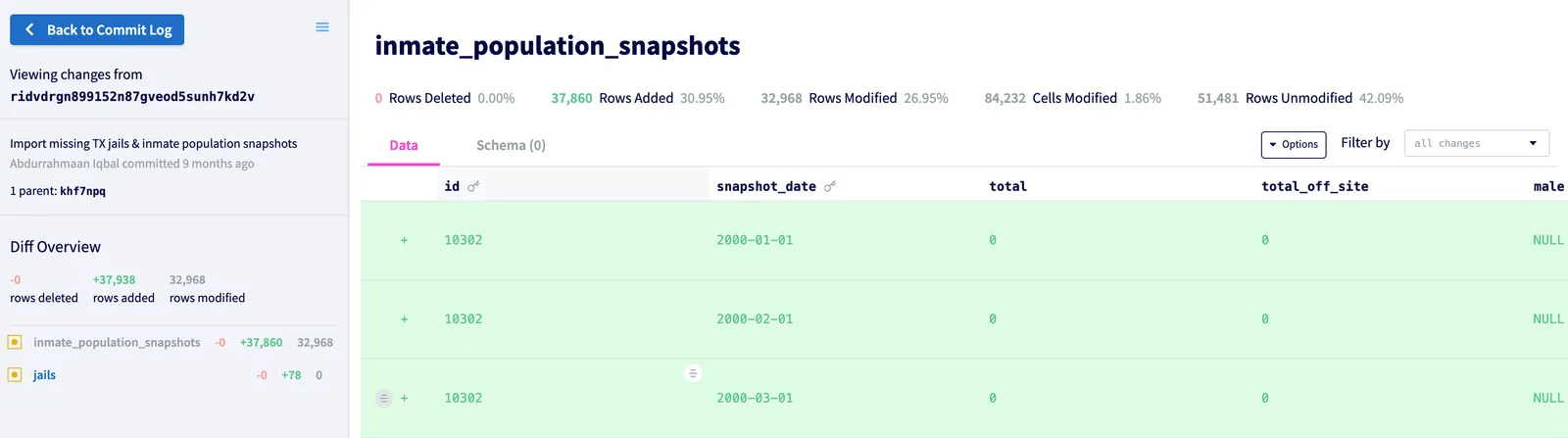
dolt_diff_stat (previously dolt_diff_summary) calculates the data difference stat
between any two commits in the database. It looks like this:
mysql> select * from dolt_diff_stat('ridvdrgn899152n87gveod5sunh7kd2v', 'khf7npqht6rjc561sjs2q4f9qpsg16k3');
+-----------------------------+-----------------+------------+--------------+---------------+-------------+---------------+----------------+---------------+---------------+----------------+----------------+
| table_name | rows_unmodified | rows_added | rows_deleted | rows_modified | cells_added | cells_deleted | cells_modified | old_row_count | new_row_count | old_cell_count | new_cell_count |
+-----------------------------+-----------------+------------+--------------+---------------+-------------+---------------+----------------+---------------+---------------+----------------+----------------+
| inmate_population_snapshots | 51481 | 0 | 37860 | 32968 | 0 | 1400820 | 84232 | 122309 | 84449 | 4525433 | 3124613 |
| jails | 3094 | 0 | 78 | 0 | 0 | 1170 | 0 | 3172 | 3094 | 47580 | 46410 |
+-----------------------------+-----------------+------------+--------------+---------------+-------------+---------------+----------------+---------------+---------------+----------------+----------------+
2 rows in set (3.11 sec)And it is used to show statistics in the diff overview and for each table:
dolt_diff_summary#
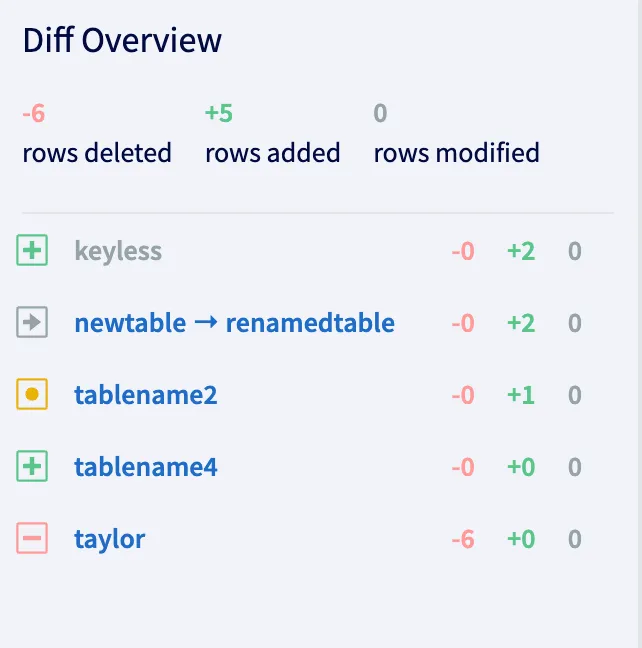
The new dolt_diff_summary table shows a summary of what tables changed and how between
two revisions. It looks like this:
mysql> select * from dolt_diff_summary('main', 'pr-test');
+-----------------+---------------+-----------+-------------+---------------+
| from_table_name | to_table_name | diff_type | data_change | schema_change |
+-----------------+---------------+-----------+-------------+---------------+
| taylor | | dropped | 1 | 1 |
| | keyless | added | 1 | 1 |
| newtable | renamedtable | renamed | 1 | 1 |
| tablename2 | tablename2 | modified | 1 | 0 |
| | tablename4 | added | 0 | 1 |
+-----------------+---------------+-----------+-------------+---------------+
5 rows in set (0.05 sec)And is used to display the tables and how they changed in the diff overview:
Before this table function existed we listed tables for each revision (SHOW TABLES AS OF '[revision]) and manually compared the lists to tell what tables changed. This was
imperfect and didn’t work well for renamed tables, which showed up separately in diffs as
an added and dropped table. This table function helped cut down a ton of code for the diff
page, improving performance and code maintainability.
dolt_patch#
dolt_patch generates the SQL statements needed to patch a table (or all tables) from a
starting revision to a target revision. It looks like this:
mysql> select * from dolt_patch('main', 'pr-test');
+-----------------+----------------------------------+----------------------------------+--------------+-----------+-----------------------------------------------------------------------------------------------------------+
| statement_order | from_commit_hash | to_commit_hash | table_name | diff_type | statement |
+-----------------+----------------------------------+----------------------------------+--------------+-----------+-----------------------------------------------------------------------------------------------------------+
| 1 | ngb5eitc0b9d807g58uqr7bi4prut9um | t4fhbg5v85biolmdnumgfrqvug555io0 | taylor | schema | DROP TABLE `taylor`; |
| 2 | ngb5eitc0b9d807g58uqr7bi4prut9um | t4fhbg5v85biolmdnumgfrqvug555io0 | keyless | schema | CREATE TABLE `keyless` ( |
| | | | | | `col0` int, |
| | | | | | `col1` varchar(255) |
| | | | | | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin; |
| 3 | ngb5eitc0b9d807g58uqr7bi4prut9um | t4fhbg5v85biolmdnumgfrqvug555io0 | keyless | data | INSERT INTO `keyless` (`col0`,`col1`) VALUES (0,'a'); |
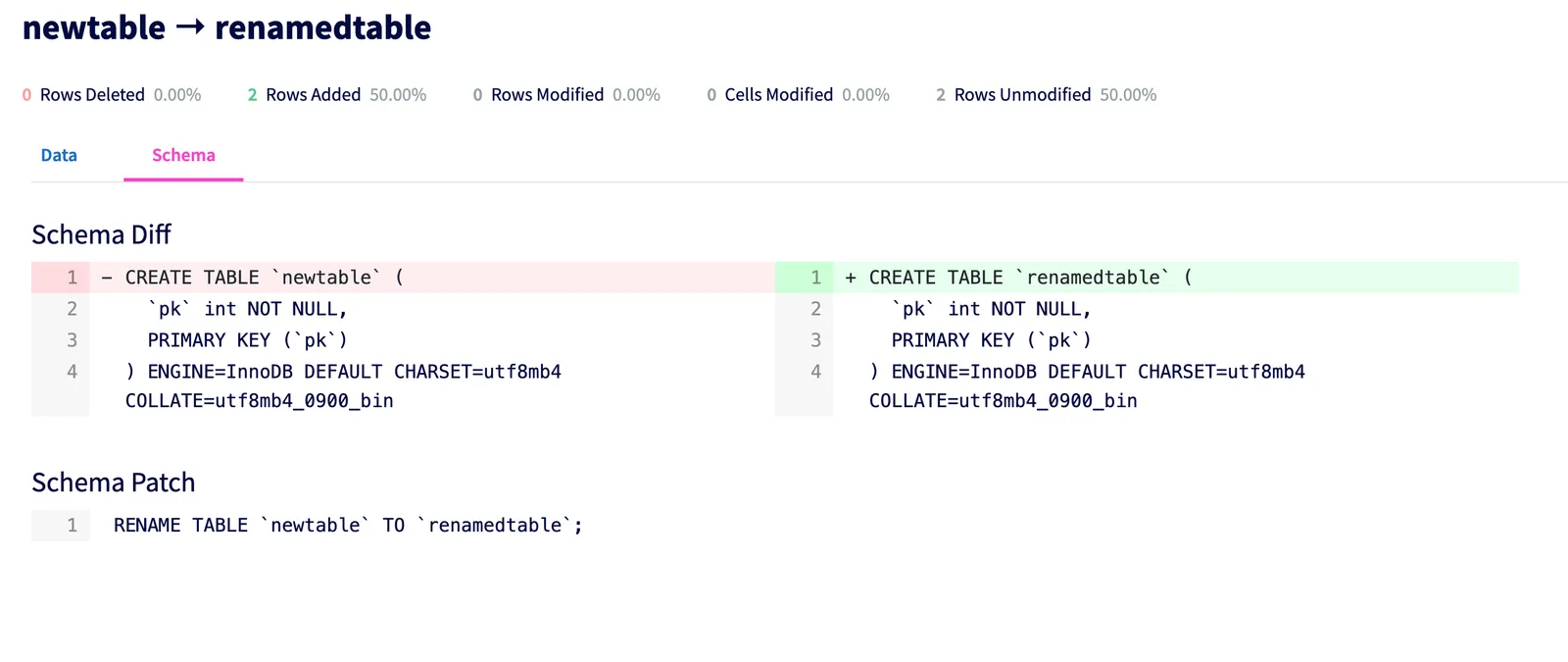
| 4 | ngb5eitc0b9d807g58uqr7bi4prut9um | t4fhbg5v85biolmdnumgfrqvug555io0 | keyless | data | INSERT INTO `keyless` (`col0`,`col1`) VALUES (1,'c'); |
| 5 | ngb5eitc0b9d807g58uqr7bi4prut9um | t4fhbg5v85biolmdnumgfrqvug555io0 | renamedtable | schema | RENAME TABLE `newtable` TO `renamedtable`; |
| 6 | ngb5eitc0b9d807g58uqr7bi4prut9um | t4fhbg5v85biolmdnumgfrqvug555io0 | renamedtable | data | INSERT INTO `renamedtable` (`pk`) VALUES (496509145); |
| 7 | ngb5eitc0b9d807g58uqr7bi4prut9um | t4fhbg5v85biolmdnumgfrqvug555io0 | renamedtable | data | INSERT INTO `renamedtable` (`pk`) VALUES (1803324686); |
| 8 | ngb5eitc0b9d807g58uqr7bi4prut9um | t4fhbg5v85biolmdnumgfrqvug555io0 | tablename2 | data | INSERT INTO `tablename2` (`pk`,`col1`) VALUES (416838400,'schema ADSL ROI Amazon bloatware firewalllll'); |
| 9 | ngb5eitc0b9d807g58uqr7bi4prut9um | t4fhbg5v85biolmdnumgfrqvug555io0 | tablename4 | schema | CREATE TABLE `tablename4` ( |
| | | | | | `pk` int NOT NULL, |
| | | | | | `col1` varchar(255), |
| | | | | | PRIMARY KEY (`pk`) |
| | | | | | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin; |
+-----------------+----------------------------------+----------------------------------+--------------+-----------+-----------------------------------------------------------------------------------------------------------+We can filter for schema-only patches using the diff_type column. This is used to get
the schema patch for diffs with schema changes:
Before this, we got the schema patch by comparing table schemas between revisions (SHOW CREATE TABLE [table] AS OF [revision]), which was also imperfect and error-prone. Stay
tuned for Jennifer’s future blog with more
details about dolt_patch!
Conclusion#
Hosted DoltDB is a great solution if you’re looking to get version control for your database and want us to do the work to host it for you. We’re continually improving the product and adding more features. If you have any feedback on the workbench or want to use Hosted Dolt for your database, make a feature request on GitHub or reach out to us on Discord.