
A couple weeks ago, somebody at Atlassian had a really bad day. Seems like they didn’t realize it at the time, but their customers noticed pretty quickly.
Can we just talk about Atlassian services being down? 🤔 What happened there? It's not a small hiccup with a few minutes or an hour-long downtime, Confluence and Jira are literally down all day.
— Mefi – Gabor Nadai (@gabornadai) Apr 5, 2022
Atlassian makes a bunch of software engineering tools that are used by a huge number of software teams around the world, and for about 400 customer businesses they stopped working on April 4. Only about half of those customers have had their service restored as of this writing, 9 days after the incident began. In addition to the project management tool Jira, affected customers lost access to OpsGenie, which handles production paging. So this outage prevented their engineering teams from getting paged in response to their own services’ outages.

Atlassian issued a statement about the extended outage, and a viral newsletter circulated a day later telling the full timeline of events and offering commentary from a customer perspective. A lot of this commentary, in that article and on various forum threads, focuses on how poorly Atlassian communicated with affected customers about the outage. This is a good point, but it masks a more important one: why did it take Atlassian 9 days and counting to fix the problem?
Root cause: human error#
Atlassian confirms that the engineer who had the really bad day made an error: he ran a script with the wrong flags and input, and that script had write access to the production database where customer data is stored.
“The script we used provided both the “mark for deletion” capability used in normal day-to-day operations (where recoverability is desirable), and the “permanently delete” capability that is required to permanently remove data when required for compliance reasons. The script was executed with the wrong execution mode and the wrong list of IDs. The result was that sites for approximately 400 customers were improperly deleted.”
Something doesn’t add up here. Surely they have backups, right? If they just deleted some data accidentally, why can’t they just restore from backup? Because nothing is ever easy.
Using these backups, we regularly roll-back individual customers or a small set of customers who accidentally delete their own data. And, if required, we can restore all customers at once into a new environment.
What we have not (yet) automated is restoring a large subset of customers into our existing (and currently in use) environment without affecting any of our other customers.
Within our cloud environment, each data store contains data from multiple customers. Because the data deleted in this incident was only a portion of data stores that are continuing to be used by other customers, we have to manually extract and restore individual pieces from our backups.
So that’s the problem: the deleted data was comingled with other customers’ data, which continued to receive updates after the backup point. If they simply restored from backup, it would wipe days’ worth of data from their other customers, which would be even worse. Instead, they have to laboriously extract and restore each customer’s data from the backup, one piece at a time.
What can we learn from this mistake, and how can we ensure it doesn’t happen to our own applications?
The limits of restoring from backup#
Pretty much every database offers backups. In the worst case, you take backups manually on some schedule with cron or another scheduling tool. In the best case, backups are taken automatically, and restoring from a previous point in time is integrated into the product. Microsoft SQL Server, for example, has offered this capability for over a decade (assuming you provision the database with the correct options to enable this feature).
But no matter how fast and reliable your restore-from-backup process is, it doesn’t help you in Atlassian’s nightmare scenario. There are two characteristics that make it so intractible:
- The error wasn’t immediately noticed, and updates had continued in the meantime
- No customer sharding, so it wasn’t possible to restore from backup for a single customer without impacting others
The worst part is that both of these factors are incredibly common. It’s easy for most of us to imagine a script misbehaving (or us fat-fingering a key) and not figuring out until later, and almost nobody runs a separate logical database for each of their customers, for a variety of very good reasons.
If you’re not worried about this class of error, you really should
be. As righteous as customers’ anger towards Atlassian is, the truth
is that it really could have happened to anyone. As a wise builder
once said (paraphrasing), “Let he who is without WHERE clause throw
the first stone.”
As an industry, we’ve spent a lot of effort protecting our databases
against natural disaster. A meteor can score a direct hit on
us-west-2 and we won’t lose any data or suffer downtime. But for
human error? If anything, the risks now are worse than they were 30
years ago, when DBAs were more common. One intern with slightly
elevated access permissions can cause a 9-day (and counting) outage by
running a script wrong. Our CEO talks about this all the time:
And indeed: we have invented a novel solution to this problem.
Zero-downtime partial rollbacks using a version-controlled database#
We’re building Dolt, the world’s first SQL database you can branch and merge, fork and clone, push and pull just like a git repository. These capabilities have a bunch of interesting use cases unrelated to disaster recovery, but it’s particularly good for that. This is because it uses the the same Merkle DAG storage that git does, making it possible to revert the effects of any bad query or set of queries without disturbing what came after.
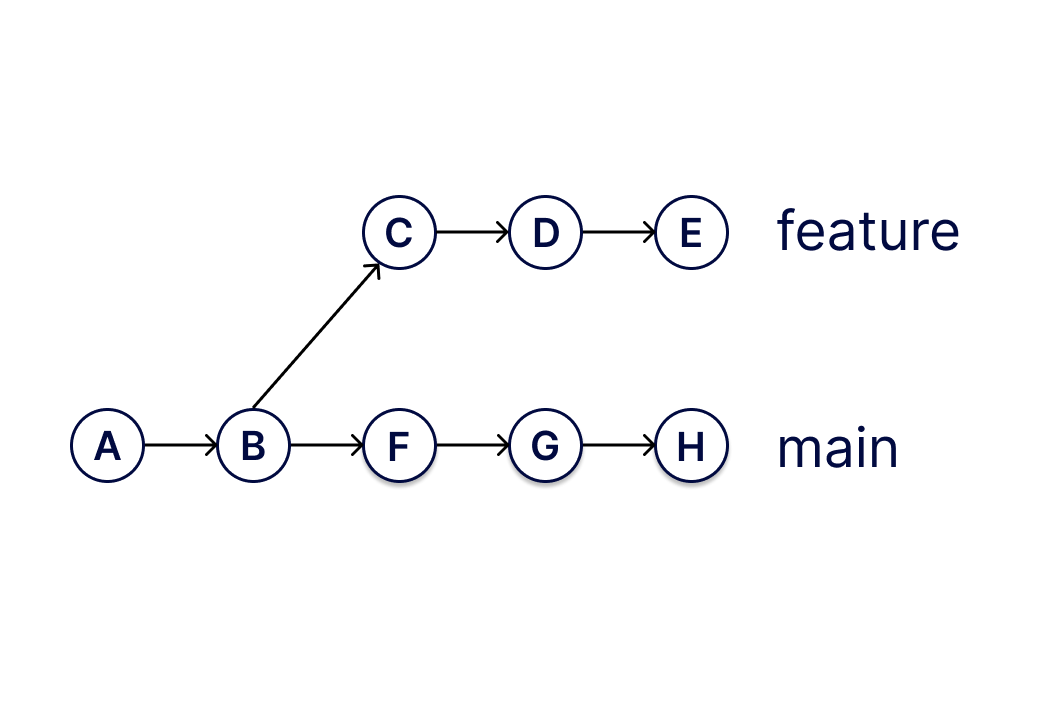
Let’s see how this works in practice. Here’s our unlucky intern’s connection to the database.
production_db> DELETE FROM CUSTOMERS WHERE CUST_ID IN ('nope', 'wrong', 'bro stop');
Query OK, 400 rows affected
production_db> SELECT DOLT_COMMIT('-am', 'Routine maintenance');Our intern goes home for the day. Customer complaints start to roll in, but by the time anyone realizes the extent of the damage, almost a full day has passed. How do you undo the damage?
First, let’s examine the commit log.
production_db> select * from dolt_log where committer = 'Intern' order by date limit 1;
+----------------------------------+---------------+------------------+-----------------------------------+----------------------+
| commit_hash | committer | email | date | message |
+----------------------------------+---------------+------------------+-----------------------------------+----------------------+
| un9njo4nc9j8ns3so05hhfp50rsolq83 | Intern | intern@your.com | 2022-04-05 14:51:04.724 -0700 PDT | Routine maintenance |
+----------------------------------+---------------+------------------+-----------------------------------+----------------------+OK, there’s our culprit. Now that we have the commit we want to revert, we query the diff table to see which tables were affected.
production_db> select table_name from dolt_diff where commit_hash = 'un9njo4nc9j8ns3so05hhfp50rsolq83';
+-------------------+
| table_name |
+-------------------+
| customers |
| jira_projects |
| billing_details |
| ops_genie_config |
+-------------------+Something tells me Atlassian has quite a few more tables than this in
their production database, but let’s start here. To figure out which
customers were deleted, even if we don’t know what query got run, we
can query the dolt_diff system table for the customers table.
production_db> select cust_id from dolt_diff_customers where to_commit = 'un9njo4nc9j8ns3so05hhfp50rsolq83' and diff_type = 'deleted';
+----------+
| cust_id |
+----------+
| nope |
| wrong |
| bro stop |
+----------+With these customer ids, we can start un-doing the damage in subsidiary tables, one customer at a time. This is easy to script.
production_db> insert into jira_projects (select * from jira_projects AS OF 'un9njo4nc9j8ns3so05hhfp50rsolq83~' where cust_id = 'nope');Note the syntax AS OF 'un9njo4nc9j8ns3so05hhfp50rsolq83~', which
queries from the jira_products table as it existed at the commit
before the disastrous one. (~ appended to a hash or branch reference
in git names the first parent of that commit, and Dolt supports this
syntax as well).
There’s an even easier way to do this though: just invoke the built-in
dolt_revert function with the culprit commit:
production_db> select dolt_revert('un9njo4nc9j8ns3so05hhfp50rsolq83');dolt_revert works just like git revert does on the command line:
it generates a patch that reverts the changes effected by the commit
named. For most schemas, that’s probably where we would start. For
disaster recovery on more complicated schemas, or just to go more
slowly and cautiously, one customer at a time, we would use the
multi-step process with the dolt_diff tables above, verifying our
repair work on a smaller scale every step of the way.
Customer sharding the easy way, with branches#
Recall the two factors that made the Atlassian disaster so painful for them to recover:
- The error wasn’t immediately noticed
- No customer sharding
Customer sharding isn’t appropriate for every application, but where it works, it’s great: it really limits the blast radius of all sorts of operational problems so that they only affect a subset of your customers (ideally just one). If Atlassian had customer sharding, they could have easily restored just the affected customers’ databases from backup without impacting anyone else.
One big reason this pattern isn’t more common is that it’s difficult to manage. Even setting aside provisioning separate hosts for each shard, just managing the namespaces and any shared data or schema is challenging. Generally there’s some shared data for all customers (domain objects, etc.), and as you evolve your schema you have to duplicate that work on each shard, timing that rollout with updated software to use it. It’s a lot of work.
Dolt simplifies this process by letting you use a branch for each
customer shard. Your main branch has the shared schema and data, and
each customer branch periodically does a merge with main to pick up
changes. Each customer’s data exists only on its respective branch,
and each branch has its own commit history.
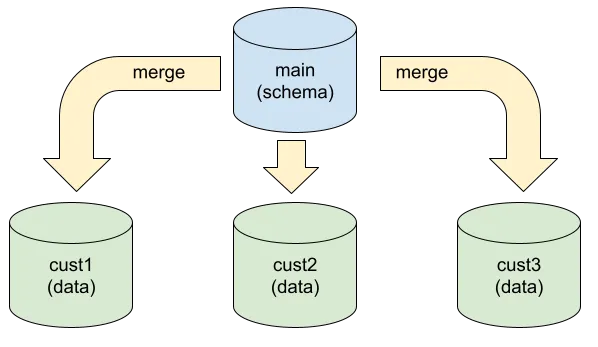
With this setup, recovering a particular customer is dirt simple,
since there is no other customer’s data on the impacted branch. It’s
just a dolt reset to the previous commit, which works exactly the
same as git reset.
use `production_db/cust1`;
select dolt_reset('--hard', 'HEAD~');As an added bonus, each branch can run on any server without
sacrificing the ability to do further branch, merge, clone,
etc. operations. Migrating a customer to dedicated hardware is as easy
as running dolt clone on the new box.
Conclusion#
Accidents happen. As an industry, we’ve spent a lot of effort making
sure that our data can survive earthquakes and tsunamis, but precious
little making sure it can survive an intern with sudo.
We’re here to share the good news that there’s a better way to administer databases, and we’ll keep telling everyone who gives us an opening. A better world is possible, if you just let Dolt into your heart.

Interested? Come chat with us on our Discord. Let’s get you started building your next application on top of a Dolt database.