
We originally built Dolt because we thought that existing data distribution formats were broken. In particular, we believed that consumers of data should not have to parse various formats (CSV, JSON, etc.), write ingestion logic and decide on update semantics simply to acquire data. Dolt envisioned data arriving along with a SQL query interface via dolt clone. We imagined Dolt as a piece of “drop in” infrastructure that allowed users to get data into production systems almost immediately.
As part of our effort to standup a community around Dolt, we have a Discord server (which you join us on!) where users can come and discuss their use-cases, or whatever else they please, with us. Not surprisingly we have learned our users have envisioned using Dolt in ways we did not anticipate. One particular use case we are going to highlight in this blogpost is using Dolt as an internal service for versioning tabular data formats, here we use Pandas DataFrame objects.
In the balance of this post we show how to standup a simple REST API that allows users to version those DataFrame objects robustly. Pandas is a popular library for manipulating tabular data in Python. It is often the case that the output of a model a researcher is producing is Pandas DataFrame containing keys and values, for example a list of stocks and associated weights that make up a portfolio.
Architecture#
In this example we use Flask, a “micro web framework” written in Python. It is simple to use, and does not require tools or libraries. It also has no database abstraction layer, so it’s relatively easy to define REST endpoints and provide some code for fulfilling the requests. Our architecture will look something like this:
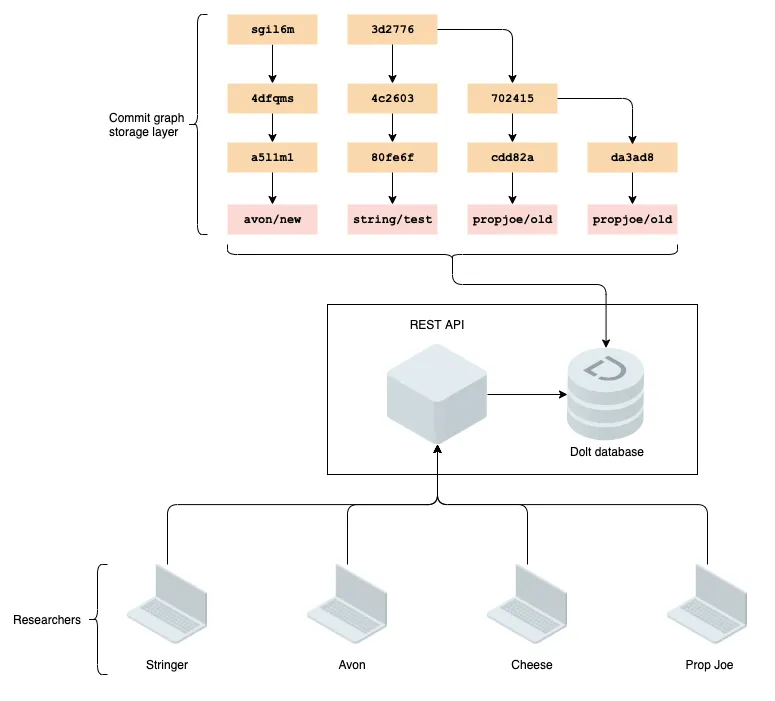
The goal of this architecture is to expose Dolt’s powerful branching and commit graph primitives to allow researchers to robustly checkpoint their work, and rollback backwards and forwards when necessary. This enables researchers can work independently at their own pace, before later using Dolt’s merging tools to robustly merge their results in with those of their teammates. All of this is repeatable and recoverable, with no risk of data loss, as all writes to the API generate a commit. We will also examine how to use DoltHub, a hosting and collaboration platform for Dolt, to host and manage various researcher branches via web interface.
The goal here is not to write a production grade service, but rather to show how little code is needed to build complex data versioning tools when building on top of Dolt. Before starting, following along requires that you have Python and pip installed.
The Server#
In the example we implement a very simple REST API on top of Flask. We provide three routes:
@app.route('/api/update_table', methods=['POST'])
@app.route('/api/create_table', methods=['POST'])
@app.route('/api/read_table', methods=['GET'])Each of them interacts with Dolt via doltpy, the Python API for Dolt that we blogged about last week. To get the server working, clone the example code and use pip to install the required dependencies:
$ git clone git@github.com:dolthub/dolt-rest-example.git
Cloning into 'dolt-rest-example'...
remote: Enumerating objects: 6, done.
remote: Counting objects: 100% (6/6), done.
remote: Compressing objects: 100% (4/4), done.
remote: Total 6 (delta 0), reused 6 (delta 0), pack-reused 0
Receiving objects: 100% (6/6), done.
$ cd dolt-rest-example
$ pip install -r requirements.txt
.
.
.
$ dolt init
$ python app.py --dolt-dir=$(pwd)
11-11 10:36:15 doltpy.core.dolt INFO Creating engine for Dolt SQL Server instance running on 127.0.0.1:3306
* Serving Flask app "app" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: on
11-11 10:36:15 werkzeug INFO * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
11-11 10:36:15 werkzeug INFO * Restarting with statYou now have the web sever running on 127.0.0.1:5000, and can start reading and writing Pandas data frames to Dolt and from tables.
The Client#
Let’s demonstrate how to interact with this server by hitting each one of the end points.
Setup#
First we need a few Python imports to get ourselves going, as well as some test data and a variable to store the URL for our API.
import requests
import pandas as pd
API_URL = 'http://127.0.0.1:5000/api'
sample_data = pd.DataFrame(
[
{'id': 1, 'name': 'BoJack Horseman'},
{'id': 2, 'name': 'Mr Peanutbutter'}
]
)Let’s dive into reading and writing data!
Create#
To start we will create a table with our initial test data. We provide a dict instance with the required parameters: the branch to add our table to, the table name, and the primary keys for our newly created table since Dolt primary keys. Finally we provide a data value that is a list of dicts:
payload = {
'branch': 'new-branch',
'table': 'characters',
'primary_keys': ['id'],
'data': sample_data.to_dict('rows')
}
result = requests.post('{}/create_table'.format(API_URL), json=payload)Behind the scenes our server imports the data, creating a table, and creates a commit on the Dolt commit graph for the database at which the table was created. Thus we now have a branch on our database called new-branch with a table called characters. Note that the branch did not previously exist, the API created it.
Read#
Let’s read that data back from the API. We no longer need to provide primary keys or data, since we aren’t creating or updating a table:
payload = {'branch': 'new-branch', 'table': 'characters'}
data = requests.get('{}/read_table'.format(API_URL), json=payload)
df = pd.DataFrame(data.json())The returned JSON can be turned into a DataFrame by passing the list of dict objects to a pd.DataFrame(...) constructor.
Update#
Let’s define an additional character for our characters table, but write it to a new branch to illustrate the power of using branches to create workspaces:
additional_data = pd.DataFrame(
[
{'id': 3, 'name': 'Princess Caroline'}
]
)
payload = {
'base_branch': 'new-branch',
'write_branch': 'another-branch',
'table': 'characters',
'data': additional_data.to_dict('rows')
}
data = requests.get('{}/update_table'.format(API_URL), json=payload)As noted above we specified a base-branch and a write-branch, which will ensure our update to the characters table takes place on a separate branch. We wrote update endpoint to support branch for simply updating the specified branch, or alternatively base_branch and write_branch for allowing users to update an existing DataFrame in a new branch. This allows researchers to collaborate without interfering with one another’s experiments.
There we have it: we have created, read, and updated a table representing a DataFrame via a REST API. This is obviously not production grade code, it is purposefully minimal to elevate the architecture.
Dolt#
Now that we have reviewed the primitive operations that our users can perform, let’s assume that we have a number of branches on our Dolt service.
One way to combine this data, or move data from one branch, say stringer/proposed-model-update to production/master-model is via the dolt merge command. A user wishing to do this would view the diffs via the Dolt command line, and then merge them. This is fine for a smaller team, but may not scale well.
This is where DoltHub’s collaboration and hosting tools for Dolt can help.
DoltHub#
DoltHub is a hosting and collaboration platform for Dolt that provides a pull request workflow familiar to anyone that has used GitHub. We can use DoltHub to perform the merges we described in the previous step by having our REST API service periodically push to DoltHub:
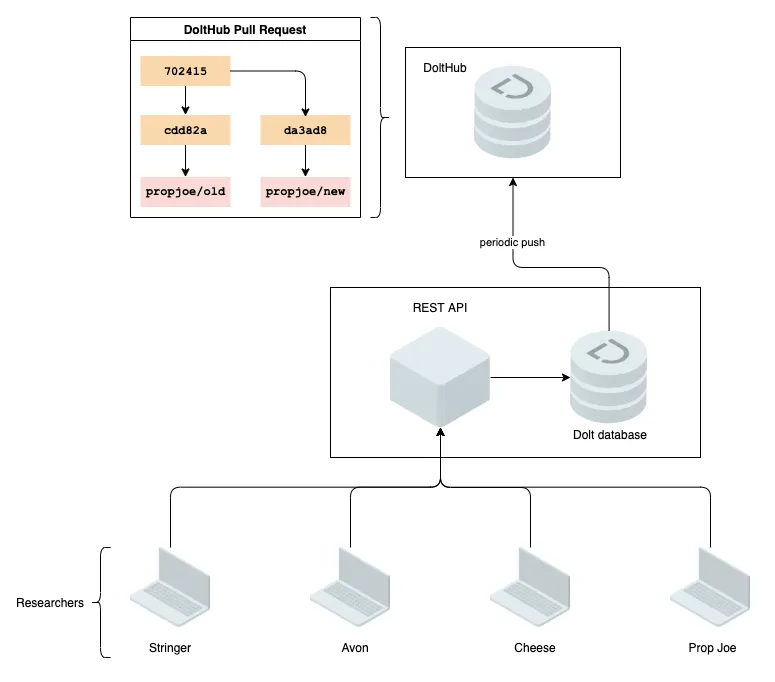
The mechanism for setting up this push is simple, the machine where the REST service is running just needs to run simple Python statement:
from doltpy.core import Dolt
dolt = Dolt('path/to/database')
for branch in dolt.branch():
dolt.push(branch.name)Once the data is pushed to DoltHub it is available for other services to clone, or it can be queried via the DoltHub API. For example, for example a production model might pull the latest data from production-model branch of the database periodically. You can read more about how to use DoltHub for collaboration here.
Conclusion#
The goal of this blog has been to show how to use Dolt’s novel features of branches and an underlying commit graph to build a simple service to enable researchers to checkpoint their results. We provided sample code for a working Flask application, albeit a barebones one. This showed the power of Dolt’s core features, and what differentiates it as a relational database.
We then briefly illustrated how to use DoltHub as a collaboration and storage layer, providing a robust hosting solution and UI for managing the various branches that researchers use as workspaces.