
Dolt is Git for Data, a SQL database you can branch, merge, clone, fork, sync, push and pull. Today we’re excited to announce a major new SQL feature: support for triggers!
What’s a trigger?#
Triggers are basically little SQL code snippets that you can set to run every time a row is inserted, updated, or deleted from a particular table. They receive the value of the row being inserted / update / deleted like a parameter, and can change it in some cases. Here are some simple examples using this new feature in Dolt:
% dolt sql
# Welcome to the DoltSQL shell.
# Statements must be terminated with ';'.
# "exit" or "quit" (or Ctrl-D) to exit.
trigger_blog> create table a (x int primary key);
trigger_blog> create table b (y int primary key);
trigger_blog> create trigger adds_one before insert on a for each row set new.x = new.x + 1;
trigger_blog> insert into a values (1), (3);
Query OK, 2 rows affected
trigger_blog> select * from a;
+---+
| x |
+---+
| 2 |
| 4 |
+---+
trigger_blog> create trigger inserts_into_b after insert on a for each row insert into b values (new.x * 2);
trigger_blog> insert into a values (5);
Query OK, 1 row affected
trigger_blog> select * from b;
+----+
| y |
+----+
| 12 |
+----+
trigger_blog>Basically any legal SQL statement can run as part of a trigger. They
can run either before or after some action (INSERT, UPDATE, or
DELETE), and you can modify the value of the row being inserted /
updated with SET new.col = newValue. We do this in the example
above: the first trigger changes any INSERTed row to increment any
value being inserted. Then the second trigger, when it refers to the
value being inserted with new.x, gets this new value.
For full documentation on the feature and lots more examples, refer to the MySQL documentation on the topic. Our goal is to match MySQL’s implementation exactly.
Triggers in Dolt#
Like views before them, triggers are stored in a normal Dolt table that you can inspect and merge like any other. After running the commands in the example above, my working set looks like this:
% dolt status
On branch master
Untracked files:
(use "dolt add <table|doc>" to include in what will be committed)
new table: a
new table: b
new table: dolt_schemasI can query the contents of this new table to see the new triggers I created:
% dolt sql -q 'select * from dolt_schemas'
+----+---------+----------------+-----------------------------------------------------------------------------------------------+
| id | type | name | fragment |
+----+---------+----------------+-----------------------------------------------------------------------------------------------+
| 1 | trigger | adds_one | create trigger adds_one before insert on a for each row set new.x = new.x + 1 |
| 2 | trigger | inserts_into_b | create trigger inserts_into_b after insert on a for each row insert into b values (new.x * 2) |
+----+---------+----------------+-----------------------------------------------------------------------------------------------+I can even use SQL INSERT, UPDATE, and DELETE to modify these
entries (although that’s an advanced use case and we don’t recommend
it).
Dolt’s really only responsible for storing triggers created in the order received. All the rest of the magic of triggers happens in go-mysql-server, which is the general-purpose SQL query engine we write to support Dolt’s SQL functionality.
What are triggers good for?#
Triggers are a general tool, but they are most commonly used to
enforce complex constraints that can’t be expressed by foreign keys,
nullness, types, or the check syntax. This is an alpha release to
get this feature into your hands as early as possible, so Dolt doesn’t
yet support some of the syntax needed to express some of these
constraints, such as the IF / ELSE syntax. But here’s a simple
example of using triggers to prevent an insert if the new row has a
value outside a range defined by another table:
create trigger check_max before insert on widgets
for each row
begin
if new.id < 0 or new.id > (select max(id) from allowed_ids where widget_category = new.category)
then
signal sqlstate '45000'; -- not yet supported in Dolt
end if;
end;It’s also common to use triggers to add zero-touch audit logging to your tables:
create trigger log_updates after update on widgets
for each row insert into widget_updates values (old.widget_description, new.widget_description)Of course, since Dolt stores your database state at every commit, you probably wouldn’t bother doing this.
You can even do something wacky like create a trigger that stops people from updating your domain tables without breaking their existing applications:
create trigger no_touch before update on universal_constants
for each row set new.value = old.value;Implementation details#
To make triggers work in the
go-mysql-server SQL
engine, there were two main pieces we had to sort out. First, we had to
give trigger bodies access to the NEW and OLD row references. This
was pretty easy since we had already implemented
sub-queries:
it’s the exact same trick to inject an outside-scope set of values
during analysis. It looks something like this:
func getTriggerLogic(ctx *sql.Context, a *Analyzer, n sql.Node, scope *Scope, trigger *plan.CreateTrigger) (sql.Node, error) {
var triggerLogic sql.Node
switch trigger.TriggerEvent {
...
case sqlparser.UpdateStr:
scopeNode := plan.NewProject(
[]sql.Expression{expression.NewStar()},
plan.NewCrossJoin(
plan.NewTableAlias("old", getResolvedTable(n)),
plan.NewTableAlias("new", getResolvedTable(n)),
),
)
triggerLogic, err = a.Analyze(ctx, trigger.Body, (*Scope)(nil).newScope(scopeNode).withMemos(scope.memo(n).MemoNodes()))
...
}As you can see, we’re just running the entire Analyzer on the
trigger body, passing in references to NEW and OLD via the outer
scope mechanism. We also use a new mechanism called “memos,” just to
keep track of whether we encounter any circular trigger
dependencies. (Without this precaution, it’s possible for the query
planner to run out of memory generating an infinitely deep query
plan.)
After we’ve analyzed the trigger logic, it’s just a matter of updating the query plan to insert the trigger execution node. Recall that query plans are trees of Node objects. They look like this for a subquery:
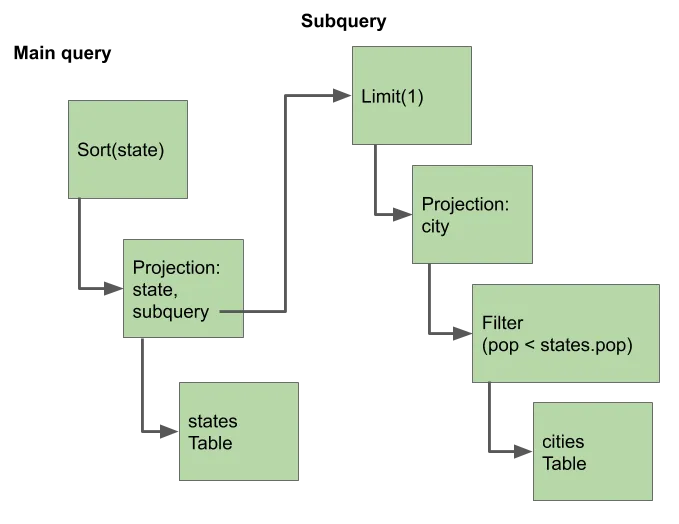
For the trigger analysis, our goal is to wrap any Insert, Update,
or Delete nodes with the appropriate triggers executor
nodes. BEFORE triggers get wrapped by the node itself (essentially
becoming the input node for an INSERT or other node), while AFTER
triggers wrap the primary operation. When multiple triggers are
defined on a table, things can get pretty complicated, with trigger
executors wrapping each other to arbitrary depths. But when it all
comes together, it’s a thing of beauty.
Here’s a complicated set of triggers
create table a (x int primary key);
create table b (y int primary key);
insert into b values (1), (3);
create trigger a1 before insert on a for each row set new.x = new.x + 1;
create trigger a2 before insert on a for each row precedes a1 set new.x = new.x * 2;
create trigger a3 before insert on a for each row precedes a2 set new.x = new.x - 5;
create trigger a4 before insert on a for each row follows a2 set new.x = new.x * 3;
-- order of execution should be: a3, a2, a4, a1
create trigger a5 after insert on a for each row update b set y = y + 1;
create trigger a6 after insert on a for each row precedes a5 update b set y = y * 2;
create trigger a7 after insert on a for each row precedes a6 update b set y = y - 5;
create trigger a8 after insert on a for each row follows a6 update b set y = y * 3;
-- order of execution should be: a7, a6, a8, a5
insert into a values (1), (3);
-- If we apply the triggers correctly, the values in the tables should be:
-- a: -23, -11
-- b: -167, -95And here’s the query plan that gets generated for the insert statement that sets off the chain of triggers, shown with the enhanced debug printing I developed while implementing subqueries:
RowUpdateAccumulator
└─ Trigger(create trigger a5 after insert on a for each row update b set y = y + 1)
├─ Trigger(create trigger a8 after insert on a for each row follows a6 update b set y = y * 3)
│ ├─ Trigger(create trigger a6 after insert on a for each row precedes a5 update b set y = y * 2)
│ │ ├─ Trigger(create trigger a7 after insert on a for each row precedes a6 update b set y = y - 5)
│ │ │ ├─ Insert()
│ │ │ │ ├─ Table(a)
│ │ │ │ └─ Trigger(create trigger a1 before insert on a for each row set new.x = new.x + 1)
│ │ │ │ ├─ Trigger(create trigger a4 before insert on a for each row follows a2 set new.x = new.x * 3)
│ │ │ │ │ ├─ Trigger(create trigger a2 before insert on a for each row precedes a1 set new.x = new.x * 2)
│ │ │ │ │ │ ├─ Trigger(create trigger a3 before insert on a for each row precedes a2 set new.x = new.x - 5)
│ │ │ │ │ │ │ ├─ Values([1 (TINYINT)],
│ │ │ │ │ │ │ │ [3 (TINYINT)])
│ │ │ │ │ │ │ └─ SET [new.x, idx=0, type=INT, nullable=false] = [new.x, idx=0, type=INT, nullable=false] - 5 (TINYINT)
│ │ │ │ │ │ └─ SET [new.x, idx=0, type=INT, nullable=false] = [new.x, idx=0, type=INT, nullable=false] * 2 (TINYINT)
│ │ │ │ │ └─ SET [new.x, idx=0, type=INT, nullable=false] = [new.x, idx=0, type=INT, nullable=false] * 3 (TINYINT)
│ │ │ │ └─ SET [new.x, idx=0, type=INT, nullable=false] = [new.x, idx=0, type=INT, nullable=false] + 1 (TINYINT)
│ │ │ └─ Update
│ │ │ └─ UpdateSource(SET [b.y, idx=1, type=INT, nullable=false] = [b.y, idx=1, type=INT, nullable=false] - 5 (TINYINT))
│ │ │ └─ Table(b)
│ │ └─ Update
│ │ └─ UpdateSource(SET [b.y, idx=1, type=INT, nullable=false] = [b.y, idx=1, type=INT, nullable=false] * 2 (TINYINT))
│ │ └─ Table(b)
│ └─ Update
│ └─ UpdateSource(SET [b.y, idx=1, type=INT, nullable=false] = [b.y, idx=1, type=INT, nullable=false] * 3 (TINYINT))
│ └─ Table(b)
└─ Update
└─ UpdateSource(SET [b.y, idx=1, type=INT, nullable=false] = [b.y, idx=1, type=INT, nullable=false] + 1 (TINYINT))
└─ Table(b)Like I said: a thing of great beauty.
Next steps#
To follow up this basic trigger functionality, we’ll be adding support
for IF / ELSE and other stored procedure syntax. There are also a
number of silly limitations to this alpha release that we’re fixing
right now:
- Can’t drop triggers after creating them
SHOW TRIGGERSdoesn’t workinformation_schema.triggerstable isn’t there- Various validation issues (like referring to a non-existent trigger in a
PRECEDESclause)
We’re also going to add support for the SIGNAL statement, which is
basically MySQL’s way of throwing an exception during stored procedure
execution.
Conclusion#
Dolt’s goal is to support 100% of MySQL’s functionality, and triggers is an important step in that direction. Not everyone uses triggers, but the people who do tend to feel very strongly about it.
If you haven’t tried Dolt yet, give it shot by installing Dolt, or chat with us on Discord. We’re always happy to hear from new customers!