
Happy Valentines Day from all of us at DoltHub! You are the reason we do what we do!

In honor of the holiday, we want to talk about how much we love making queries faster. We’re going to examine how our SQL engine makes a query plan and explain how we optimized it to make joins faster. We hope you love reading our story!
Adopting go-mysql-server#
Dolt uses an open-source SQL engine called go-mysql-server. We chose it because it was the leading go-native SQL execution engine at the time we went looking for one. We wanted a go-native solution because Dolt is written in go, and we wanted to ensure Dolt users don’t have to do anything other than install the dolt binary to start using SQL out of the box. Since adopting it, we’ve forked it and have made many improvements. One of our latest was to implement logic for indexed joins, which makes join on primary key columns several orders of magnitude faster.
Before we dive into how we did this, we need to understand a little bit about how go-mysql-server works.
How go-mysql-server builds a query plan#
Let’s assume we start with the following query:
SELECT col1, avg(col2) as b FROM a
WHERE col1 > 10
GROUP BY col1
ORDER BY b
LIMIT 200;go-mysql-server breaks the execution of a query down into three distinct phases.
Parse#
The parse phase takes the SQL query string and transforms it into an abstract syntax tree (AST), a data structure that reflects the structure of the query. After parsing, we end up with an AST that looks like this:
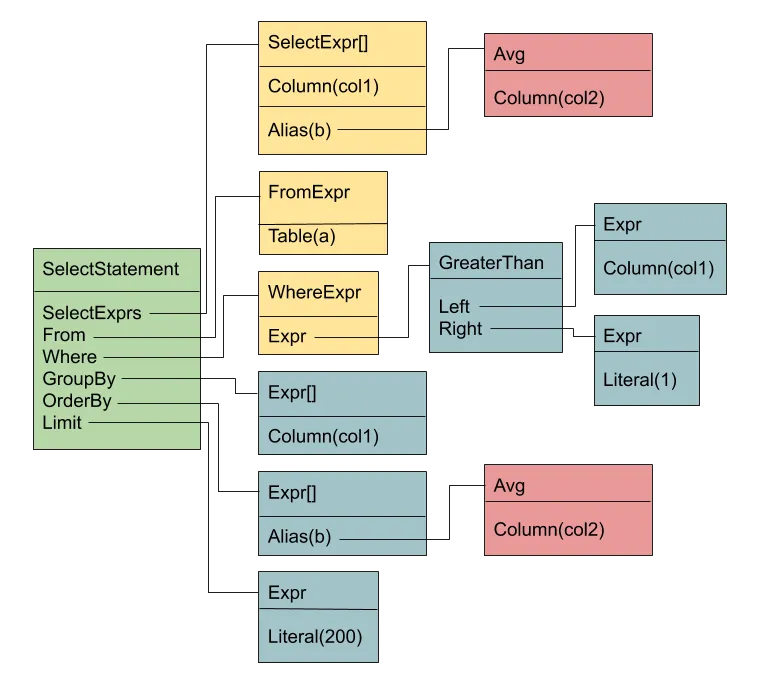
Transform to sql.Nodes#
Next, the AST is walked to assemble a parallel structure of
Nodes. Nodes are a go-mysql-server data structure that knows how
to return rows for the part of the query plan it represents. This
step’s job is just to faithfully represent the exact structure of the
AST as a tree of Nodes. This gives us a Node representation of the
tree that looks like this:
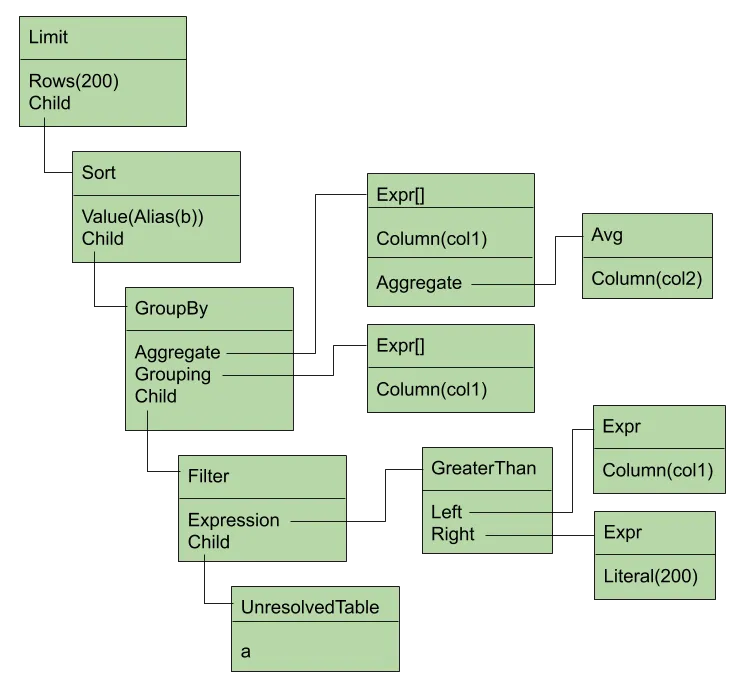
Analyze#
Finally, the tree of Nodes is transformed through a series of
bottom-up transformation functions to give the final tree of Nodes,
which represents the actual query plan. This analysis step is very
involved and does everything from resolving table and column
names
to pushing where clauses down onto their source
tables. This
gives us the final representation of the tree, which looks like this:
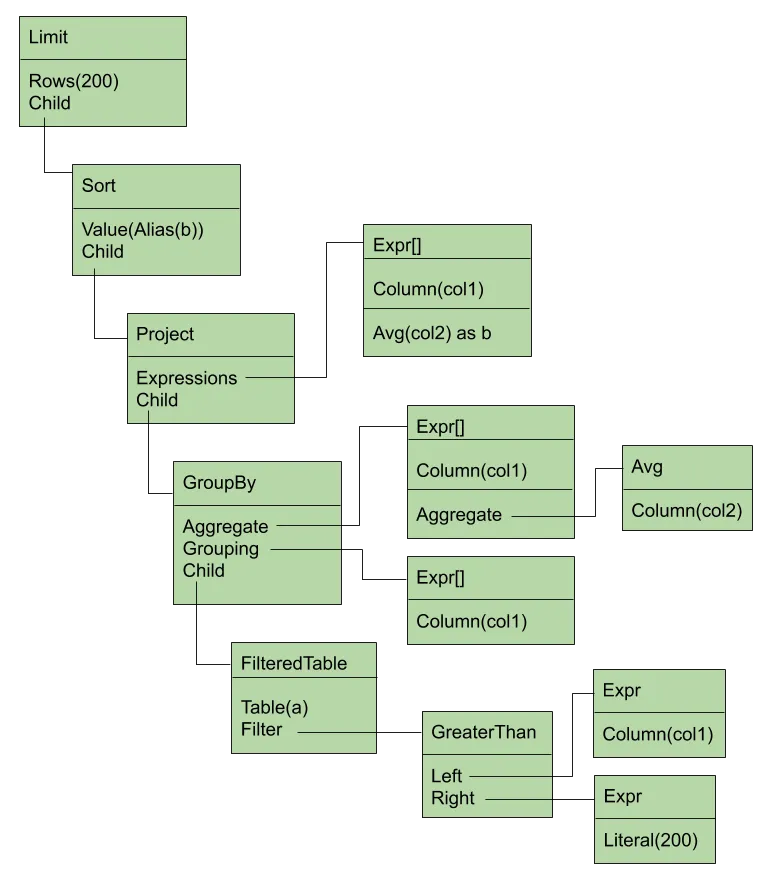
The analyzed tree looks a lot like the parsed tree, except that it added a projection (to select a subset of columns from the child node) and it pushed the filter operation down onto the table itself. This latter move doesn’t matter much for this query, but any time a join is involved, pushing a filter down onto its origin table can make execution much faster.
Textual representation of query plans#
Now that we are familiar with how the SQL engine creates an execution plan, we’ll switch to a more compact, textual format for the rest of this post. This is the same format Dolt uses when you ask it to explain a query:
doltsql> explain SELECT col1, avg(col2) as b FROM a where col1 > 10 group by col1 order by b LIMIT 200;
+------------------------------------------------+
| plan |
+------------------------------------------------+
| Limit(200) |
| └ Sort(b ASC) |
| └ Project(a.col1, AVG(a.col2) as b) |
| └ GroupBy |
| ├ Aggregate(a.col1, AVG(a.col2)) |
| ├ Grouping(a.col1) |
| └ Filter(a.col1 > 10) |
| └ a |
+------------------------------------------------+InnerJoins to IndexedJoins#
go-mysql-server has long supported indexes, and will use them to avoid
a full table scan if they appear in a WHERE clause. But indexes
weren’t being used in the execution of joins, and there weren’t plans
to do so. This
means that joins always had quadratic performance — a full table scan
of the secondary table for every row in the primary table (with disk
access on every scan for big tables). In practice, this meant that
even moderately sized tables, on the order of tens of thousands of
rows, couldn’t be joined together in a reasonable amount of time. This
was a major barrier to Dolt’s
utility as a SQL engine, so we decided we needed to fix it.
As you might have guessed, the implementation involved a new stage in
the Analyzer, to replace InnerJoins with IndexedJoins where
possible. The heart of this
transformation
looks like this:
func transformJoins(a *Analyzer, n sql.Node, indexes map[string]sql.Index, aliases Aliases) (sql.Node, error) {
node, err := plan.TransformUp(n, func(node sql.Node) (sql.Node, error) {
a.Log("transforming node of type: %T", node)
switch node := node.(type) {
case *plan.InnerJoin, *plan.LeftJoin, *plan.RightJoin:
var cond sql.Expression
var bnode plan.BinaryNode
var joinType plan.JoinType
switch node := node.(type) {
case *plan.InnerJoin:
cond = node.Cond
bnode = node.BinaryNode
joinType = plan.JoinTypeInner
case *plan.LeftJoin:
cond = node.Cond
bnode = node.BinaryNode
joinType = plan.JoinTypeLeft
case *plan.RightJoin:
cond = node.Cond
bnode = node.BinaryNode
joinType = plan.JoinTypeRight
}
primaryTable, secondaryTable, primaryTableExpr, secondaryTableIndex, err := analyzeJoinIndexes(bnode, cond, indexes, joinType)
if err != nil {
a.Log("Cannot apply index to join: %s", err.Error())
return node, nil
}
joinSchema := append(primaryTable.Schema(), secondaryTable.Schema()...)
joinCond, err := fixFieldIndexes(joinSchema, cond)
if err != nil {
return nil, err
}
secondaryTable, err = plan.TransformUp(secondaryTable, func(node sql.Node) (sql.Node, error) {
a.Log("transforming node of type: %T", node)
if rt, ok := node.(*plan.ResolvedTable); ok {
return plan.NewIndexedTable(rt), nil
}
return node, nil
})
if err != nil {
return nil, err
}
return plan.NewIndexedJoin(primaryTable, secondaryTable, joinType, joinCond, primaryTableExpr, secondaryTableIndex), nil
default:
return node, nil
}
})
return node, err
}There’s a lot going on here, so let’s examine it step by step.
First, plan.TransformUp is a function that walks the execution tree
from the bottom up, running a function you specify for each
Node. You return a new Node to replace the current one, as
necessary. The switch statement that begins the function shows that
we’re only interested in transforming certain classes of Nodes,
namely those that implement joins.
node, err := plan.TransformUp(n, func(node sql.Node) (sql.Node, error) {
a.Log("transforming node of type: %T", node)
switch node := node.(type) {
case *plan.InnerJoin, *plan.LeftJoin, *plan.RightJoin:Next, we analyze the two tables in the join to figure out which indexes we can apply (more on this in a moment), and also to determine which table to use as the primary, and which as the secondary. We must examine every row in the primary, and use it to look up rows in the secondary table using an index.
primaryTable, secondaryTable, primaryTableExpr, secondaryTableIndex, err := analyzeJoinIndexes(bnode, cond, indexes, joinType)Finally, we replace the ResolvedTable node for the secondary table
with an IndexedTable node to make accessing it simpler in the actual
join code.
secondaryTable, err = plan.TransformUp(secondaryTable, func(node sql.Node) (sql.Node, error) {
a.Log("transforming node of type: %T", node)
if rt, ok := node.(*plan.ResolvedTable); ok {
return plan.NewIndexedTable(rt), nil
}
return node, nil
})Conceptually, this is relatively straightforward. In practice, there were lots of wrinkles that it took a while to sort out, and many bugs we found and squashed. We were very grateful to have our test suite of 5.7 million SQL queries to give us confidence we weren’t introducing errors into the execution logic.
Choosing the right index for a join#
For our first pass, we decided to focus on just equality conditions on all the columns in the primary key of a table. go-mysql-server already provides an interface for declaring indexes on a table, which we won’t go into. The interesting part is finding which of the declared indexes can be used in a join.
func getJoinIndexes(e sql.Expression, aliases map[string]sql.Expression, a *Analyzer) (map[string]sql.Index, error) {
switch e := e.(type) {
case *expression.Equals:
result := make(map[string]sql.Index)
leftIdx, rightIdx := getJoinEqualityIndex(a, e, aliases)
if leftIdx != nil {
result[leftIdx.Table()] = leftIdx
}
if rightIdx != nil {
result[rightIdx.Table()] = rightIdx
}
return result, nil
case *expression.And:
exprs := splitConjunction(e)
for _, expr := range exprs {
if _, ok := expr.(*expression.Equals); !ok {
return nil, nil
}
}
return getMultiColumnJoinIndex(exprs, a, aliases), nil
}
return nil, nil
}
func getJoinEqualityIndex(
a *Analyzer,
e *expression.Equals,
aliases map[string]sql.Expression,
) (leftIdx sql.Index, rightIdx sql.Index) {
// Only handle column expressions for these join indexes. Evaluable expression like `col=literal` will get pushed
// down where possible.
if isEvaluable(e.Left()) || isEvaluable(e.Right()) {
return nil, nil
}
leftIdx, rightIdx =
a.Catalog.IndexByExpression(a.Catalog.CurrentDatabase(), unifyExpressions(aliases, e.Left())...),
a.Catalog.IndexByExpression(a.Catalog.CurrentDatabase(), unifyExpressions(aliases, e.Right())...)
return leftIdx, rightIdx
}
func getMultiColumnJoinIndex(exprs []sql.Expression, a *Analyzer, aliases map[string]sql.Expression, ) map[string]sql.Index {
result := make(map[string]sql.Index)
exprsByTable := joinExprsByTable(exprs)
for table, cols := range exprsByTable {
idx := a.Catalog.IndexByExpression(a.Catalog.CurrentDatabase(), unifyExpressions(aliases, extractExpressions(cols)...)...)
if idx != nil {
result[table] = idx
}
}
return result
}In getJoinIndexes, we examine the condition of a join node to see if
we can use an index on either of the tables in the condition. We only
support two kinds of expressions here: simple equality, and
conjunctions (AND). In the case of the latter we try to match every
part of the conjunction to produce a single index across multiple
columns.
Once we know which indexes to use for the join, it’s just a matter of
choosing a primary and secondary table. Note that we need to consider
the join type (LEFT or RIGHT or INNER) here, because e.g. the
left table in a LEFT join must always be considered the primary
table. This function looks more complicated than it is: really it’s
just asserting the LEFT and RIGHT join constraints we just
mentioned, and swapping the left and right tables as necessary so that
the secondary table is on the right.
// Analyzes the join's tables and condition to select a left and right table, and an index to use for lookups in the
// right table. Returns an error if no suitable index can be found.
func analyzeJoinIndexes(
node plan.BinaryNode,
cond sql.Expression,
indexes map[string]sql.Index,
joinType plan.JoinType,
) (primary sql.Node, secondary sql.Node, primaryTableExpr []sql.Expression, secondaryTableIndex sql.Index, err error) {
leftTableName := findTableName(node.Left)
rightTableName := findTableName(node.Right)
exprByTable := joinExprsByTable(splitConjunction(cond))
// Choose a primary and secondary table based on available indexes. We can't choose the left table as secondary for a
// left join, or the right as secondary for a right join.
if indexes[rightTableName] != nil && exprByTable[leftTableName] != nil && joinType != plan.JoinTypeRight {
primaryTableExpr, err := fixFieldIndexesOnExpressions(node.Left.Schema(), extractExpressions(exprByTable[leftTableName])...)
if err != nil {
return nil, nil, nil, nil, err
}
return node.Left, node.Right, primaryTableExpr, indexes[rightTableName], nil
}
if indexes[leftTableName] != nil && exprByTable[rightTableName] != nil && joinType != plan.JoinTypeLeft {
primaryTableExpr, err := fixFieldIndexesOnExpressions(node.Right.Schema(), extractExpressions(exprByTable[rightTableName])...)
if err != nil {
return nil, nil, nil, nil, err
}
return node.Right, node.Left, primaryTableExpr, indexes[leftTableName], nil
}
return nil, nil, nil, nil, errors.New("couldn't determine suitable indexes to use for tables")
}Finding the row in the secondary table#
Finally we come to the guts of the implementation, where we get to evaluate every row in the primary table and use the join condition to look up an index on the secondary table. The code is pretty straightforward:
func (i *indexedJoinIter) loadSecondary() (sql.Row, error) {
if i.secondary == nil {
// evaluate the primary row against the primary table expression to get the secondary table lookup key
var key []interface{}
for _, expr := range i.primaryTableExpr {
col, err := expr.Eval(i.ctx, i.primaryRow)
if err != nil {
return nil, err
}
key = append(key, col)
}
lookup, err := i.index.Get(key...)
if err != nil {
return nil, err
}
err = i.secondaryIndexAccess.SetIndexLookup(i.ctx, lookup)
if err != nil {
return nil, err
}
span, ctx := i.ctx.Span("plan.IndexedJoin indexed lookup")
rowIter, err := i.secondaryProvider.RowIter(ctx)
if err != nil {
span.Finish()
return nil, err
}
i.secondary = sql.NewSpanIter(span, rowIter)
}
secondaryRow, err := i.secondary.Next()
if err != nil {
if err == io.EOF {
i.secondary = nil
i.primaryRow = nil
return nil, io.EOF
}
return nil, err
}
return secondaryRow, nil
}So first, we evaluate the primary table’s expression against the
primary table row to get all the elements of the index key. Once we
have it, we call i.secondaryIndexAccess.SetIndexLookup(lookup) with
the resulting index lookup, which informs the IndexedTable to start
iterating with that key on the next call to Node.RowIter. Then when
all the rows for that key are exhausted, secondary and primaryRow
are both set to null, which makes the iterator move on to the next row
in the primary table.
Next steps#
This optimization makes it feasible to run two-table joins in a
reasonable amount of time, and it works for arbitrarily complex
queries. For example, in our last blog
post we
demonstrated how complex a query execution plan can get when joining
multiple views together on our COVID19
dataset. Note
that the query planner uses IndexedJoins for all the view subqueries,
which is what makes the query performant.
doltsql> explain select * from current;
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| plan |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| SubqueryAlias(current) |
| └─ Sort(current_cases.cases DESC) |
| └─ Project(current_cases.country, current_cases.state, current_cases.cases, current_deaths.deaths, current_recovered.recovered) |
| └─ LeftJoin(current_cases.country = current_recovered.country AND current_cases.state = current_recovered.state) |
| ├─ LeftJoin(current_cases.country = current_deaths.country AND current_cases.state = current_deaths.state) |
| │ ├─ SubqueryAlias(current_cases) |
| │ │ └─ Sort(cases ASC) |
| │ │ └─ Project(country, state, MAX(convert(cases.observation_time, datetime)) as last updated, cases) |
| │ │ └─ GroupBy |
| │ │ ├─ Aggregate(places.country_region as country, places.province_state as state, MAX(convert(cases.observation_time, datetime)), cases.confirmed_count as cases) |
| │ │ ├─ Grouping(cases.place_id) |
| │ │ └─ Filter(NOT(cases.confirmed_count IS NULL)) |
| │ │ └─ IndexedJoin(cases.place_id = places.place_id) |
| │ │ ├─ cases |
| │ │ └─ places |
| │ └─ SubqueryAlias(current_deaths) |
| │ └─ Sort(deaths DESC) |
| │ └─ Project(country, state, MAX(convert(cases.observation_time, datetime)) as last updated, deaths) |
| │ └─ GroupBy |
| │ ├─ Aggregate(places.country_region as country, places.province_state as state, MAX(convert(cases.observation_time, datetime)), cases.death_count as deaths) |
| │ ├─ Grouping(cases.place_id) |
| │ └─ Filter(NOT(cases.death_count IS NULL)) |
| │ └─ IndexedJoin(cases.place_id = places.place_id) |
| │ ├─ cases |
| │ └─ places |
| └─ SubqueryAlias(current_recovered) |
| └─ Sort(recovered DESC) |
| └─ Project(country, state, MAX(convert(cases.observation_time, datetime)) as last updated, recovered) |
| └─ GroupBy |
| ├─ Aggregate(places.country_region as country, places.province_state as state, MAX(convert(cases.observation_time, datetime)), cases.recovered_count as recovered) |
| ├─ Grouping(cases.place_id) |
| └─ Filter(NOT(cases.recovered_count IS NULL)) |
| └─ IndexedJoin(cases.place_id = places.place_id) |
| ├─ cases |
| └─ places |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+We think this is pretty cool. But there’s more work to do:
- Indexes can only be used for two-table joins. Add a third table and we can’t use an index.
- Dolt’s only supports indexes on primary keys, which limits the utility of this optimization. We plan to support user-defined index creation on any columns in a table in the near future.
- Some simple use cases are still buggy. For example, it’s still not possible join a table to itself.
We’re excited to get to work on these improvements. If you think of more, file an issue or a PR and let us know!